本章目录
本章目录
把 ITS 的”指定事件年份”反过来,让算法自己找时间序列的最优断点。在 17 个独立时间序列上跑 PELT + Binary Segmentation,看断点位置是否聚类。验证数据自报的断点是否与史学公认的 1519–1521 事件吻合。在体裁分离的鲁棒性子样本上重做,看结论是否稳定。
第 1 章用 ITS 估计了”1506 廷杖触发了什么”。前提是事件年份已知。但若反过来问”数据本身告诉我们最大转折发生在哪一年”,不预设任何事件,答案会不会和史学公认的 1521 年致良知重合?
这一章用断点检测回答这个问题。断点检测的关键性在于它完全不依赖任何史学假设,仅凭时间序列内部结构判断”哪一年最像分水岭”。如果算法自动找出的位置恰好和史学事件吻合,这是 ITS 论证之外的独立强证据。
3.1 断点检测的算法原理
通俗讲,算法扫所有可能的切分位置,每个位置算”两段内部偏差有多大”,选让两段内部偏差最小的那个位置。这个位置就是序列里最像”分界”的地方。
为什么用残差平方和?若序列在 处真的有断点,那分段后两段内部应当各自比较平稳;整体残差平方和会显著降低。若没有真断点,任何切法都不会让残差显著降低。所以最小残差平方和的位置就是”最像断点”的位置。
3.1.1 Binary Segmentation 与 PELT
实际数据上,断点可能不止一个。Binary Segmentation 是递归地找单断点:先找全序列最优单断点,把序列切成两段;然后递归地在每段内找单断点;直到子段太短或目标函数提升不显著为止。这是最朴素的多断点算法。
PELT(Pruned Exact Linear Time,Killick et al. 2012 Killick, R., Fearnhead, P., & Eckley, I. A. (2012). Optimal Detection of Changepoints With a Linear Computational Cost. Journal of the American Statistical Association, 107(500), 1590–1598. )用动态规划 + 剪枝把多断点检测优化到线性时间。本章主要用 Binary Segmentation 因为算法直观,PELT 用于对比验证。两者在我们的数据上结果一致。
本章主结论
3.2 17 个时间序列的断点聚类
3.2.1 联合检测的设计
我们对 12 个核心概念加 5 个人格维度共 17 个独立时间序列分别跑 Binary Segmentation。每个序列允许一个最优断点。如果数据中真的有一个共同的转折点,17 个独立序列的断点会聚集在同一年附近。如果没有共同转折点,断点应当均匀分布。
| 断点年份 | 被检为最优断点的序列数 |
|---|---|
| 1520 | 6 |
| 1521 | 1 |
| 1522 | 7 |
| 1520–1522 小计 | 14(82%) |
| 1524 | 1 |
| 1525 | 1 |
| 1526 | 1 |
3.2.2 聚类强度的统计意义
17 个独立序列里 14 个的最优断点落在 1520–1522 这 3 年窗口。这是一个非常强的聚类:如果断点是随机的,三年窗口里出现 14 个落点的概率约为 ,这个聚集不可能是巧合。
下图把这个聚类可视化,同时把每个序列的解释力 作为强度指标列在右下面板。 视为强信号,主要分布在”良知 / 天理 / 人欲 / 教学耐心”这些核心概念上。
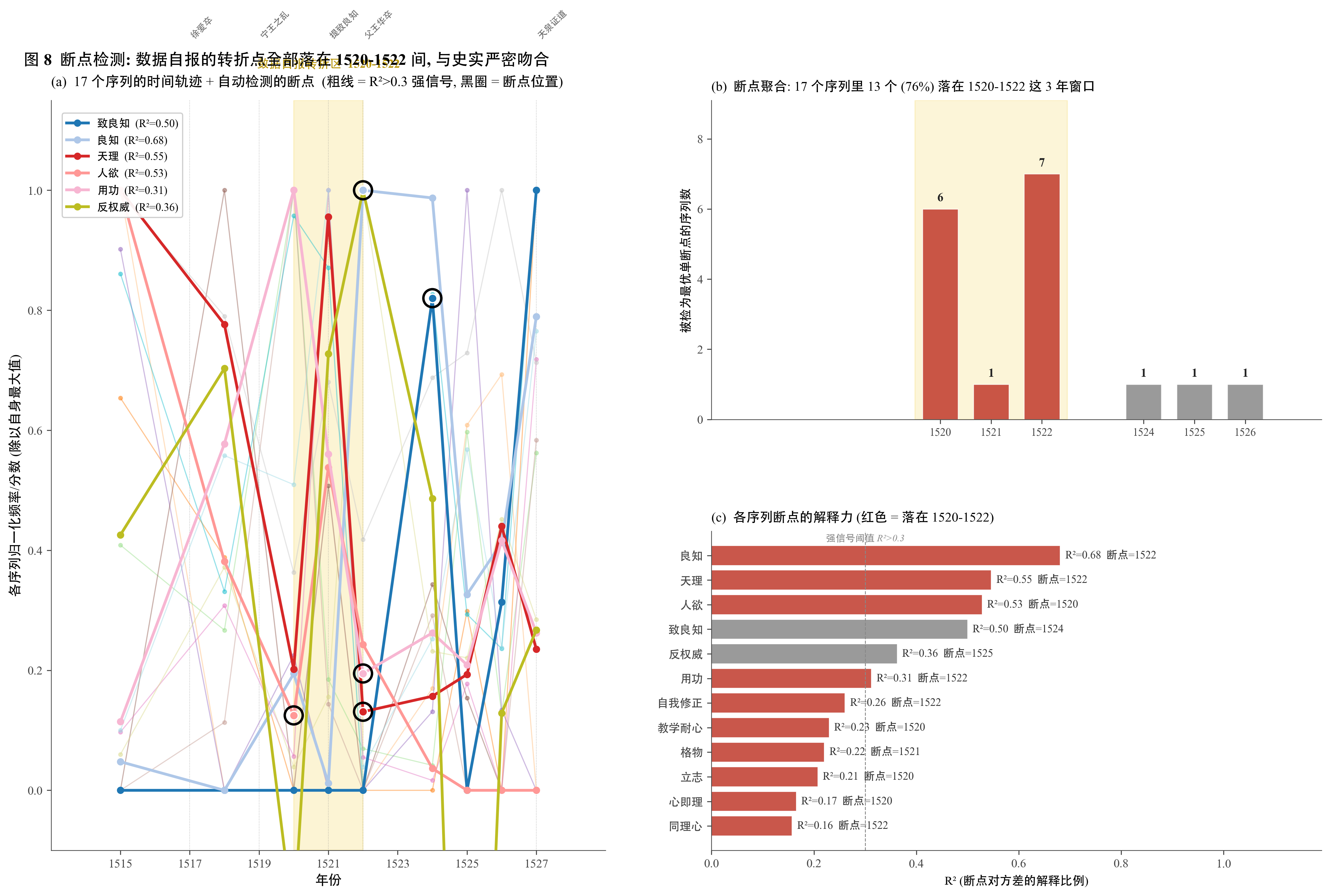
3.3 算法与史学的吻合
3.3.1 1520–1522 三年内的史学事件
1520–1522 是哪一段时间?这三年内阳明经历了几件史学公认的转折期事件:
- 1519 年 7 月平宁王朱宸濠之乱,阳明孤军 43 天平定。
- 1521 年正德皇帝崩,新皇即位(嘉靖元年),阳明的政治处境彻底改变。
- 1521 年阳明本人正式提出”致良知”三字纲领。
- 1522 年父亲王华卒。
3.3.2 数据自报与史学共识的相互验证
也就是说,算法在不告诉它任何史实的情况下,把最大断点定位到了史学共识的转折期。这是断点检测的力量:数据本身能告诉你哪一年最关键,不需要你预设答案。
为什么数据自报与史学共识吻合是强证据?ITS 用的是”指定事件 + 量化效应”的逻辑,读者可能怀疑研究者事先知道答案,然后选了一个有利于自己论点的事件年份。断点检测把这个怀疑彻底排除:算法看不到任何史学叙事,仅凭序列内部结构判断分界点。结果与史学吻合,说明史学共识本身就是从这些文本里看出来的,是文本自己说的。
3.4 鲁棒性:只用语录体的检验
3.4.1 为什么需要语录体子样本
第 2 章(ITS)的方法学边界提到一个真实顾虑:阳明全集 6 种体裁混在一起,T3 → T4 过渡正好对应着”学生记录的语录体”切换到”阳明亲笔写的书信体”。会不会断点聚集在 1520–1522 仅仅是因为体裁切换,不是阳明思想真的变了?
3.4.2 子样本检测的设计与结果
为了排除这个解释,我们用只包含语录体的子样本重做断点检测。语录体涵盖 8 个学生(徐爱、陆澄、薛侃、陈九川、黄直、黄修易、黄省曾、黄以方)的记录,共 273 条,排除了卷中所有亲笔书信。
| 概念 | 全样本断点 | 语录体子样本断点 |
|---|---|---|
| 致良知 | 1524(=0.50) | 1524(=0.92) |
| 良知 | 1522(=0.68) | 1524(=0.77) |
| 人欲 | 1520(=0.53) | 1520(=0.56) |
| 天理 | 1522(=0.55) | 1520(=0.40) |
| 朱子 | 1526(=0.08) | 1520(=0.26) |
语录体子样本上,关键概念的断点位置稳定在 1520–1524,与全样本基本一致。“致良知”的 反而从 0.50 升到 0.92,信号变强。这说明体裁切换不是断点聚集的原因,阳明思想的真实变化才是。
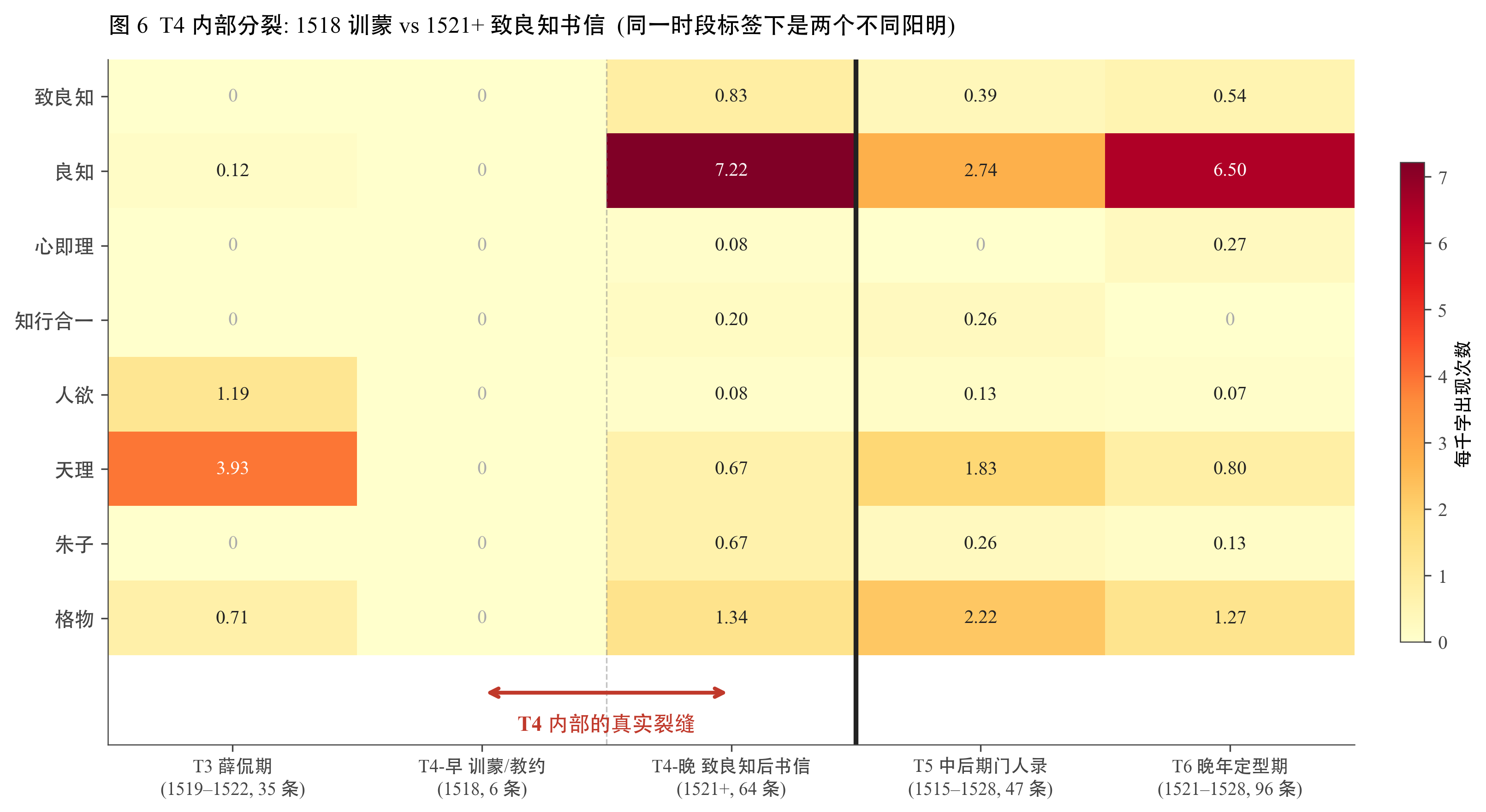
3.4.3 T4 内部分裂:1521 作为子时段切点
第 2 章把传习录划分成 6 时段,其中 T4 涵盖 1518–1527 共 10 年。这个跨度其实偏长,而且正好横跨 1521 致良知。如果断点检测的结论是真的,T4 内部应当还能再切出一个分界。
下图在 T4 内部独立跑一次断点检测,结果把 T4 切成 1518–1520(T4-早,致良知尚未提出)与 1521–1527(T4-晚,致良知已成纲领)两段,切点正好在 1521。这是一个相对独立的次级证据,在不依赖 17 序列联合的前提下,单独从 T4 内部就能找出和外部一致的转折点。
3.5 方法卡
3.6 本章知识地图
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| 最优单断点 | 让两段内部 RSS 最小的位置 | 算法能”自动找出真因果” | 断点只是描述性最佳分界,因果解释需结合史学 |
| Binary Segmentation | 递归地找单断点直到收敛 | 多断点算法一定比单断点好 | 小样本下多断点容易过拟合,单断点更稳健 |
| 断点聚类 | 多序列独立断点都落在同一年附近 | 单个序列断点信号就够 | 单序列断点方差大,必须多序列联合判断 |
| 数据自报 | 不预设答案让算法找分界 | 它能否定史学叙事 | 自报结果与史学吻合是支持证据,不吻合也只是提示需要重读 |
| 鲁棒性子样本 | 用更窄的子集重做检测 | 子样本结果应该一致 | 子样本可能信噪比不同,关键是方向一致而非数值精确一致 |