本章目录
本章目录
理解右心导管 RHC 争议的临床背景与因果推断意义,掌握 RHC 数据集的结构、关键变量与基线分布,识别观察数据中”适应证混杂”的表现形式,并能计算朴素关联又能讲清楚它为什么不能直接当作因果效应。
1996 年,Alfred Connors 和同事在 JAMA 发表了一项覆盖五所教学医院、5735 名 ICU 危重症患者的观察性研究。研究的核心发现让整个重症医学界意外:接受右心导管监测的患者,180 天死亡率比未接受 RHC 的患者高了大约 7.5 个百分点。
右心导管是一根从颈静脉或锁骨下静脉送入肺动脉的导管。它是一个实时的血流动力学探测器:心脏泵了多少血、肺动脉里的压力有多高、血液里的氧够不够用,这些信息 ICU 医生都能从导管上读到。在 Connors 的论文发表之前,绝大多数临床医生默认这些信息有助于指导治疗、改善预后。Connors 的数据呈现的方向相反:插了管的病人死得更多。
这篇论文引发的争论持续了近十年。支持者认为 RHC 本身可能带来导管相关感染、心律失常、气胸等并发症,监测信息也可能诱导过度干预。反对者则指出一个根本性的统计学问题:接受 RHC 的病人本来就更重,死亡率高也许和导管无关,纯粹是因为这群人的基线风险就高。这个问题用因果推断的语言来说,叫做适应证混杂,英文称 confounding by indication。医生决定是否插管时参考的正是病情严重程度,而病情严重程度本身又直接影响死亡率。处理变量和结局变量共享一个共同原因,观察到的关联就被污染了。
这本书只回答一个问题:RHC 是否因果地增加了 ICU 患者的 180 天死亡率? 每一章用一种不同的因果推断方法来回答它,最后汇总比较。同一份数据、同一个问题、九种不同的方法,读者可以逐章看到每种方法的假设、操作和结论有什么异同。
1.1 为什么不能做随机试验
回答因果问题最直接的办法是随机对照试验,简称 RCT。把 5735 名患者随机分成两组,一组插管、一组不插管,比较死亡率。随机化保证了两组在所有已知和未知的混杂因素上平均相同,观察到的死亡率差异就可以归因于 RHC 本身。
但 RHC 的 RCT 始终没有做成。伦理审查是第一道障碍:如果临床医生认为某个患者需要血流动力学监测,随机把他分到”不插管”组意味着剥夺了一项临床医生认为必要的诊断手段。操作上的阻力同样大,重症科医生对自己的临床判断有强烈信念,愿意让抛硬币决定自己病人是否插管的医生很少。哪怕启动了试验,知情同意的获取在危重症患者身上极其困难,患者本人往往无法签字,家属在极度焦虑中也不太可能冷静权衡研究方案。
RCT 做不了,因果问题还要回答。这就是观察性因果推断存在的理由。 因果推断方法论的现代综合,见 Hernán & Robins, Causal Inference: What If, 2020。 Connors 和同事手上有一份丰富的观察数据,记录了患者入 ICU 时的人口学特征、病史、生理指标和病情严重程度评分。利用这些协变量,我们可以尝试在统计上”模拟”随机化的效果,把适应证混杂剥离出去。接下来的九章就是九种不同的剥离策略。
1.2 因果推断的根本困难
这个框架的核心困难在于:对每一个真实的病人,我们只能观察到一个潜在结局。插了管的人看到了 ,没插管的人看到了 ,另一个永远缺失。Holland 把这件事称为”因果推断的根本问题”。个体因果效应在原理上不可识别,我们能做的只是估计总体层面的平均效应 ATE。
估计 ATE 需要用观察到的数据去填补缺失的那一列。最朴素的做法是把 RHC 组的平均结局当作 ,把非 RHC 组的平均结局当作 ,直接相减。这个做法在 RCT 中完全合法,因为随机化保证了两组可交换。但在观察数据中,RHC 组和非 RHC 组的病人构成系统性地不同,直接比较混进了混杂的成分。下面用数据来看这种”不同”到底有多大。
1.3 数据概览
本书使用的数据来自 Connors et al. (1996) 的原始研究,经过清洗后保存在 data/rhc.csv。数据集包含 5735 名 ICU 患者,49 个变量。处理变量为 rhc,取值 0 或 1;结局变量为 death180,取值 Yes 或 No。关键协变量包括 APACHE III 评分、平均动脉压、肌酐、白蛋白等生理指标,以及年龄、性别、种族、保险类型等人口学变量。
下面的代码读入数据并预览结构。
library(tidyverse)
set.seed(2026)
# 读入数据——here::here() 保证路径相对于项目根目录
d <- read_csv(here::here("data", "rhc.csv"), show_col_types = FALSE)
dim(d) # 5735 行 x 49 列
# 创建二分类结局变量
d <- d |> mutate(death180_bin = ifelse(death180 == "Yes", 1, 0))
# 预览 10 个关键变量的前 6 行
key_vars <- c("rhc", "death180", "age", "sex", "apache_score",
"blood_pressure", "creatinine", "albumin",
"heart_rate", "respiratory_rate")
head(d[, key_vars], 6)
数据有 5735 行、49 列。表 1.1 展示了前 6 名患者在 10 个关键变量上的取值。可以直观看到变量的量纲差异很大:apache_score 在 38–82 之间,blood_pressure 在 41–115 mmHg 之间,creatinine 在 0.6–3.6 mg/dL 之间。这种量纲差异意味着后续做匹配或加权时需要标准化。
| rhc | death180 | age | sex | apache | bp | creat | alb | hr | rr |
|---|---|---|---|---|---|---|---|---|---|
| 0 | No | 70.3 | Male | 46 | 41 | 1.20 | 3.50 | 124 | 10 |
| 1 | Yes | 78.2 | Female | 50 | 63 | 0.60 | 2.60 | 137 | 38 |
| 1 | No | 46.1 | Female | 82 | 57 | 2.60 | 3.50 | 130 | 40 |
| 0 | Yes | 75.3 | Female | 48 | 55 | 1.70 | 3.50 | 58 | 26 |
| 1 | Yes | 67.9 | Male | 72 | 65 | 3.60 | 3.50 | 125 | 27 |
| 0 | No | 86.1 | Female | 38 | 115 | 1.40 | 3.10 | 134 | 36 |
1.4 基线失衡:谁接受了 RHC?
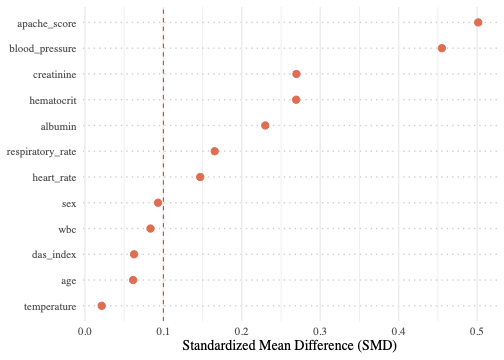
如果 RHC 的使用是随机的,RHC 组和非 RHC 组在所有基线变量上应该高度相似。要衡量现实中这两组的构成差距,需要一个指标。
标准化均值差,简称 SMD,把两组之间某个变量的均值差除以合并标准差,消除量纲的影响。SMD = 0.50 意味着处理组的均值比对照组高半个标准差,这是一个相当大的失衡。SMD = 0.10 意味着差距只有十分之一个标准差,通常被认为是可接受的平衡。超过 0.10 就提示存在需要处理的失衡。
library(tableone)
# 选取 12 个关键协变量
vars <- c("age", "sex", "apache_score", "blood_pressure",
"heart_rate", "respiratory_rate", "creatinine",
"albumin", "hematocrit", "wbc", "temperature",
"das_index")
# 按 RHC 分组计算 Table 1,同时输出 SMD
d <- d |> mutate(rhc_label = ifelse(rhc == 1, "RHC", "No RHC"))
tab1 <- CreateTableOne(vars = vars, strata = "rhc_label",
data = d, test = FALSE, smd = TRUE)
print(tab1, smd = TRUE)
表 1.2 汇总了 12 个关键协变量在两组之间的分布。RHC 组有 2184 人,非 RHC 组有 3551 人。
| 变量 | No RHC () | RHC () | SMD |
|---|---|---|---|
| Age, mean (SD) | 61.76 (17.29) | 60.75 (15.63) | 0.061 |
| Male, % | 53.9 | 58.5 | 0.093 |
| APACHE Score, mean (SD) | 50.93 (18.81) | 60.74 (20.27) | 0.501 |
| Blood Pressure, mean (SD) | 84.87 (38.87) | 68.20 (34.24) | 0.455 |
| Heart Rate, mean (SD) | 112.87 (40.94) | 118.93 (41.47) | 0.147 |
| Respiratory Rate, mean (SD) | 28.98 (13.95) | 26.65 (14.17) | 0.165 |
| Creatinine, mean (SD) | 1.92 (2.03) | 2.47 (2.05) | 0.270 |
| Albumin, mean (SD) | 3.16 (0.67) | 2.98 (0.93) | 0.230 |
| Hematocrit, mean (SD) | 32.70 (8.79) | 30.51 (7.42) | 0.269 |
| WBC, mean (SD) | 15.26 (11.41) | 16.27 (12.55) | 0.084 |
| Temperature, mean (SD) | 37.63 (1.74) | 37.59 (1.83) | 0.021 |
| DAS Index, mean (SD) | 20.37 (5.48) | 20.70 (5.03) | 0.063 |
失衡最严重的是 APACHE III 评分,SMD = 0.50,RHC 组均值 60.74 远高于非 RHC 组的 50.93。APACHE 是 ICU 常用的病情严重程度综合评分,分数越高代表病情越重、预期死亡率越高。RHC 组的 APACHE 均值比非 RHC 组高将近 10 分,换算成标准差单位就是半个标准差的差距。平均动脉压的 SMD 也达到 0.46,RHC 组血压更低,这与临床预期一致:血流动力学不稳定的病人更可能被插管监测。肌酐 SMD = 0.27,RHC 组肾功能更差。白蛋白和血球容积的 SMD 均在 0.23–0.27 之间。
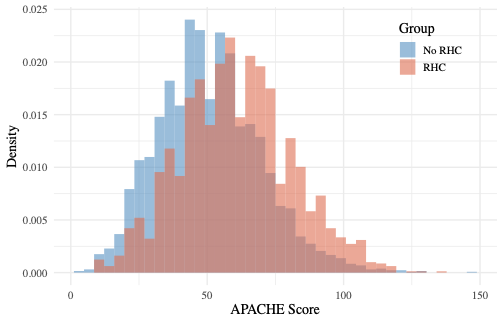
下图用密度直方图展示了两组 APACHE 评分的分布。RHC 组的分布明显右移,高分段的密度更大。这种右移直观地说明了适应证混杂的核心机制:病情越重的患者越可能被插管,而病情越重本身就意味着死亡风险越高。
Love plot 把全部 12 个协变量的 SMD 画在一张图上,红色虚线标记 SMD = 0.1 的阈值。12 个变量中有 8 个超过了 0.1,APACHE 评分和血压的失衡尤其严重。这意味着直接比较两组的死亡率,混杂的成分不可忽略。
1.5 朴素关联:粗死亡率差异
在做任何调整之前,先看最简单的数字:两组的 180 天粗死亡率各是多少?
# 按 RHC 分组计算 180 天死亡率
d |>
group_by(rhc) |>
summarise(
n = n(),
deaths = sum(death180_bin),
mortality = mean(death180_bin),
.groups = "drop"
)
非 RHC 组 3551 人中 1650 人在 180 天内死亡,死亡率 46.5%。RHC 组 2184 人中 1179 人死亡,死亡率 54.0%。粗死亡率差异为 个百分点,RHC 组更高。
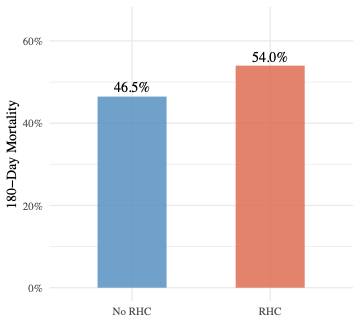
停下来想一想。 非 RHC 组死亡率 46.5%,RHC 组 54.0%,差了 7.5 个百分点。如果你是一位 ICU 主任,看到这个数字会立刻下令停用右心导管吗?在翻到下一段之前,试着列出至少一个理由,解释为什么这个差距可能不是 RHC 本身造成的。
7.5 个百分点的差距看起来不小,但它能直接被解读为”RHC 导致死亡率升高 7.5 个百分点”吗?前面的 Table 1 已经说明了答案:不能。RHC 组的 APACHE 均分高了将近 10 分,血压低了 17 mmHg,肌酐高了 0.55 mg/dL。这些指标全都指向同一个事实,RHC 组的病人入 ICU 时病情就更重。病情更重的人死亡率更高,这和导管本身无关。
1.6 全书路线图
本书用九种方法回答同一个问题。第 2 章用 DAG 梳理变量之间的因果结构,明确哪些协变量需要调整。第 3 章从最简单的回归调整开始,逐步加入协变量,观察估计值如何变化。第 4 章用 G 计算做标准化,预测反事实结局。第 5 章转向倾向得分,包括匹配、逆概率加权和重叠权重。第 6 章手动实现 AIPW,体会双重稳健的机制。第 7 章引入机器学习,用 Super Learner、DML 和 TMLE 分别估计。第 8 章做敏感性分析,回答”如果存在未观测混杂,结论还站得住吗”。第 9 章用因果森林探索异质性效应,看 RHC 对哪些亚群有害、对哪些亚群可能有益。第 10 章把所有方法的估计汇总到一张表里,比较点估计和置信区间,讨论方法之间的一致性与分歧。
每章末尾会更新一张累积对比表,格式如下。
| 方法 | ATE | 95% CI | 核心假设 | 局限 |
|---|---|---|---|---|
| 粗差异 | 0.075 | — | 无 | 未调整任何混杂 |
1.7 本章知识地图
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| 右心导管 RHC | 经静脉插入肺动脉的导管,实时监测血流动力学参数 | RHC 是一种治疗手段 | RHC 是诊断/监测工具,本身不直接改变治疗方案 |
| 适应证混杂 | 决定是否给予处理的因素同时影响结局,导致两组不可比 | 只要样本量够大,混杂就会消失 | 样本量解决的是抽样变异,混杂是系统性偏倚 |
| 潜在结果 | 每个个体在处理与不处理两种情境下各有一个潜在结局 | 潜在结果可以同时观测 | 每个个体只能处于一种处理状态,另一个潜在结局永远缺失 |
| ATE | ,总体平均处理效应 | 粗死亡率差异等于 ATE | 粗差异 = ATE + 混杂偏倚;只有随机化或充分调整后才近似 ATE |
| SMD | 标准化均值差,度量两组协变量平衡程度, 为可接受 | SMD 小就不需要调整 | 单变量平衡不代表整体平衡,要看全部协变量 |
| APACHE III | ICU 病情严重程度综合评分,本数据中 SMD = 0.50 | APACHE 是唯一的混杂因素 | 血压、肌酐、白蛋白等也有显著失衡,需要同时调整多个变量 |