本章目录
本章目录
看清 BCG 在不同地区给出矛盾答案的真实数字;学会读 2x2 表,每一格代表的是哪一群人;掌握风险比 RR 的算法与含义;理解为什么把 13 张 2x2 表直接相加不可行。
1948 年,全世界每年还有几百万人死于结核病。一种叫做卡介苗的活减毒疫苗已经在欧洲使用了二十多年,英文称 BCG,全称 Bacillus Calmette-Guérin。
1.1 BCG 卡介苗的全球效果争论
BCG 的工作原理可以这样理解。免疫系统平时不认识结核菌长什么样,等到结核菌真的进入身体,免疫系统才开始慌乱反应。BCG 是把活的、被减毒过的结核菌一次性给免疫系统看一眼,让它”认识”这种细菌的家族特征。等真正的结核菌进来时,免疫系统能一眼认出来,立刻处理掉。
这套机制的合理性看起来无可辩驳,但 BCG 在全球的实际效果争论极大。法国的研究说效果惊人,美国的研究说几乎没用,印度南部一项最大规模的随机对照试验干脆得出”完全无效”的结论。同一种疫苗,不同的研究地点,结论却天差地别。
为了让”全球结论矛盾”不只是一个抽象说法,先看三项最具代表性的试验真实给出的数字:
- Aronson 1948 在美国土著儿童 262 人里发现 BCG 把结核发病风险降低了 60%。
- Hart & Sutherland 1977 在英国 26,465 人里发现 BCG 把发病风险降低了 76%。
- TPT Madras 1980 在印度南部 176,782 人里发现 BCG 几乎完全无效。
三项都是大型随机对照试验,执行质量都不差,但答案差出了天与地。如果一位医生只读到 Aronson 这篇论文,会得到”BCG 是个非常有效的疫苗”的结论;只读到 TPT Madras 那篇,会得到”BCG 不值得推广”的结论。临床决策不能这样靠运气挑论文。要回答”BCG 在全球到底有用吗”,必须把所有相关研究放在一起整理、合并。这件事就是 meta 分析(中文常译为”元分析”或”汇总分析”)。
到了 1990 年代初,Colditz 和同事把 13 项 1948–1980 年间在世界各地完成的 BCG 随机对照试验整理成一份汇总数据集,发表在 JAMA 上。 Colditz, G. A. et al. (1994). Efficacy of BCG vaccine in the prevention of tuberculosis. JAMA, 271(9), 698–702. 这份数据后来被收进 Viechtbauer 编写的 metafor 包,称为 dat.bcg,成为 meta 分析教学的事实标准样本,相当于机器学习领域的 iris、回归分析教学里的 mtcars。**本书全书都用这一份数据。**每一章用一种 meta 分析方法处理这同一份数据,到第 10 章把所有结论汇总比较。
1.2 一项 BCG 试验的数据结构:2x2 表
每项 BCG 试验做的事其实都一样:把一群健康人随机分成两组,一组打 BCG(叫处理组),一组不打或打安慰剂(叫对照组)。隔几年看哪组发病的人更多。
每项试验完整的核心结果都可以装进一张 2 行 2 列的小表格,行业通称 2x2 表。以 Aronson 1948 这项美国土著儿童研究为例,全员 262 人,跟踪一年多结束之后的结果整理成下表。
| 后来发病了 | 后来没发病 | 这一组合计 | |
|---|---|---|---|
| 打了 BCG(处理组) | 人 | 人 | 人 |
| 没打 BCG(对照组) | 人 | 人 | 人 |
读这张表的方法是一格一类人。左上角 意思是这项试验里打了 BCG 又发病的孩子有 4 个。右上角 是打了 BCG 没发病的孩子有 119 个。左下角 是没打 BCG 又发病的 11 个。右下角 是没打 BCG 没发病的 128 个。最右边那一列是每组的总人数:处理组 ,对照组 ,加起来正好是这项试验的全部 262 人。
为什么要画这张表?因为本书后面所有 meta 分析方法,本质上都从这四个数字开始。**13 项研究就是 13 张这样的 2x2 表。**metafor 包内置的 dat.bcg 里四列数字 tpos、tneg、cpos、cneg 依次对应表 1.1 里的 、、、。本书后续章节里出现的字母 都回到这张图。
如果你能告诉别人某项试验的 、、、 四个数字各是多少,你就完整复述了这项试验的核心结果。
这就是 meta 分析整理研究数据的最小单位。
1.3 风险比 RR 的定义与计算
知道了 2x2 表的四个数字,怎么算”BCG 到底有没有用”?
最直觉的做法是看两组的发病率(也叫”事件率”),就是每组里发病的人占该组总人数的比例。Aronson 1948 里:
打了 BCG 的发病率明显比没打的低。低多少?把打了的发病率除以没打的发病率:。
这个 0.41 就叫风险比(risk ratio,简称 RR)。它的临床含义是:打了 BCG 的人发病风险只有没打 BCG 的人的 0.41 倍,相对降低了 59%。
用一个完全不需要医学背景的例子理解 RR:100 个吃辣的人里 5 个胃疼,100 个不吃辣的人里 1 个胃疼。吃辣的人胃疼”风险”是不吃辣的人的 倍。RR 就是这种”风险倍数”。
RR 的解读规则只有三条:等于 1 表示处理对结局没有影响;小于 1 表示处理有保护作用,越接近 0 保护越强;大于 1 表示处理反而增加风险。Aronson 1948 算出 RR ,落在保护区,BCG 在这项试验里把发病风险压低到原来的 41%。
1.4 13 项研究的答案一字排开
按上面的方法给每项研究算一个 RR。13 项的结果按试验地点的纬度从低到高排,列在下表。
| 编号 | 作者 | 年份 | 纬度 | BCG 组发病/总数 | 对照组发病/总数 | RR |
|---|---|---|---|---|---|---|
| 5 | Frimodt-Moller | 1973 | 13° | 33 / 5,069 | 47 / 5,808 | 0.80 |
| 8 | TPT Madras | 1980 | 13° | 505 / 88,391 | 499 / 88,391 | 1.01 |
| 11 | Comstock et al | 1974 | 18° | 186 / 50,634 | 141 / 27,338 | 0.71 |
| 7 | Vandiviere et al | 1973 | 19° | 8 / 2,545 | 10 / 629 | 0.20 |
| 9 | Coetzee & Berjak | 1968 | 27° | 29 / 7,499 | 45 / 7,277 | 0.63 |
| 12 | Comstock & Webster | 1969 | 33° | 5 / 2,498 | 3 / 2,341 | 1.56 |
| 13 | Comstock et al | 1976 | 33° | 27 / 16,913 | 29 / 17,854 | 0.98 |
| 3 | Rosenthal et al | 1960 | 42° | 3 / 231 | 11 / 220 | 0.26 |
| 10 | Rosenthal et al | 1961 | 42° | 17 / 1,716 | 65 / 1,665 | 0.25 |
| 1 | Aronson | 1948 | 44° | 4 / 123 | 11 / 139 | 0.41 |
| 6 | Stein & Aronson | 1953 | 44° | 180 / 1,541 | 372 / 1,451 | 0.46 |
| 4 | Hart & Sutherland | 1977 | 52° | 62 / 13,598 | 248 / 12,867 | 0.24 |
| 2 | Ferguson & Simes | 1949 | 55° | 6 / 306 | 29 / 303 | 0.20 |
13 项的 RR 散布从最低 (强保护,发病风险压到原来的 20%)到最高 (反而增加风险)跨度极大。这就是 1.1 节提到的”全球结论矛盾”在数字上的真实表现。
把同一份数据画成下图,每一行是一项研究,红点是 BCG 组发病率,蓝点是对照组发病率,中间用淡灰线连起来代表两组的差距。按纬度从低到高排。
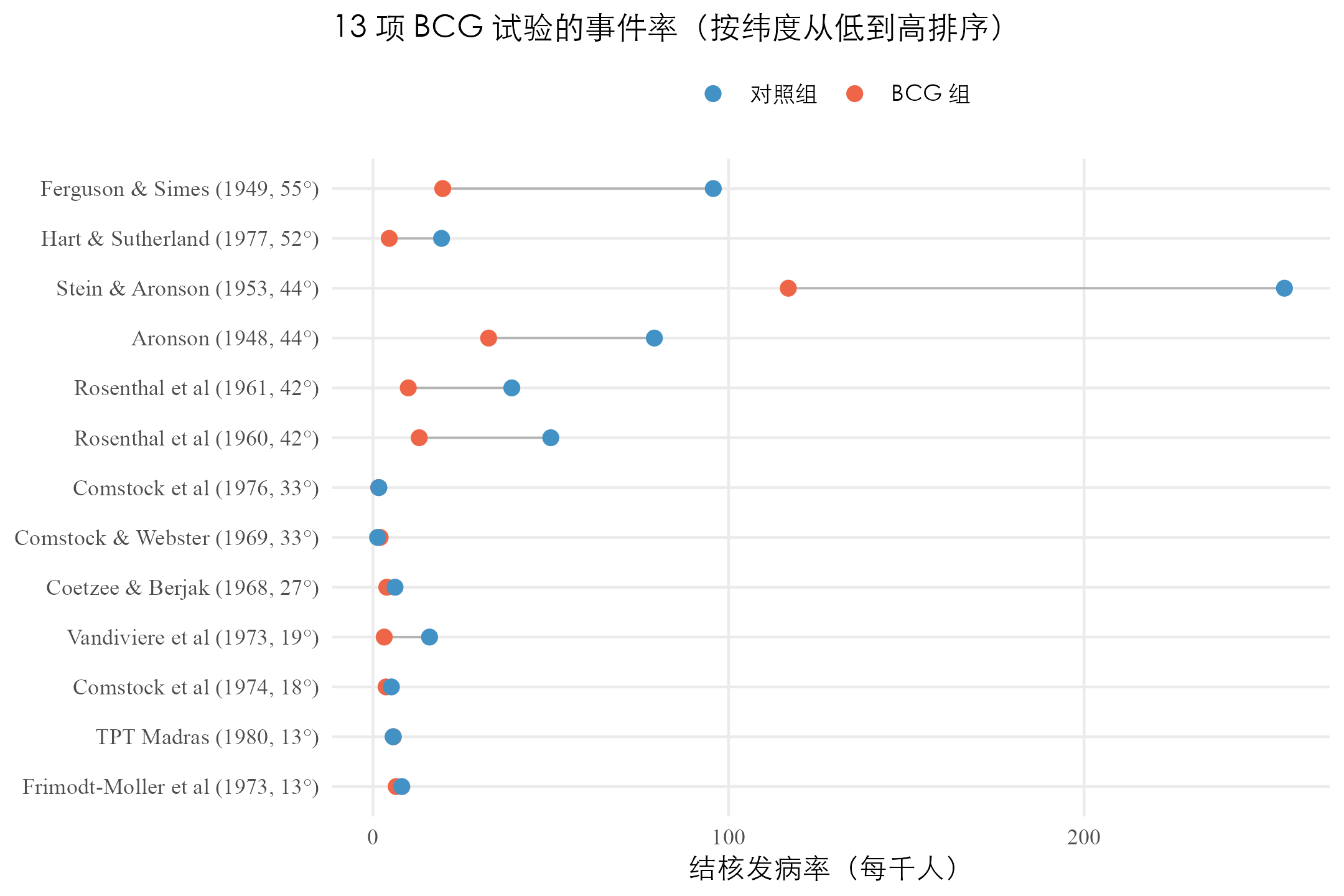
扫一眼这张表与图,会注意到一个隐藏的规律:表 1.2 按纬度排序后,上半部分(低纬度试验)RR 接近 1 或大于 1,下半部分(高纬度试验)RR 普遍在 – 之间。BCG 在赤道附近几乎没用,在高纬度地区效果显著。这个规律不是巧合,第 7 章会用纬度作为协变量解释 75% 的研究间差异。这里先记下这个伏笔。
1.5 朴素合并:把 13 张 2x2 表直接相加
13 项研究的 RR 跨度太大,没法用任何一项单独下结论。最直觉的”合并”方法是:把 13 张 2x2 表的对应格子加起来,得到一张涵盖全部 357,347 名受试者的”超级 2x2 表”,再算一个总的 RR。结果列在下表。
| 发病了 | 没发病 | 合计 | |
|---|---|---|---|
| 打了 BCG(13 项汇总) | 1,065 | 189,999 | 191,064 |
| 没打 BCG(13 项汇总) | 1,510 | 164,773 | 166,283 |
按 1.3 节的 RR 定义代入这张超级表:
看起来 BCG 平均把全球结核风险降低了 39%,结论相当乐观。这种”把所有 2x2 表直接相加”的合并方法叫朴素合并(naïve pooling)。
但 0.61 这个数字其实靠不住,问题出在样本量分布上。13 项研究最大的 TPT Madras 一项就有 176,782 人,最小的 Aronson 才 262 人,差出 670 倍。把所有 2x2 表加起来时,TPT Madras 一项就贡献了将近一半的样本。最终的合并 RR 几乎被这一项研究单独决定。
回顾表 1.2:TPT Madras 给出的 RR 是 (几乎无效),但其他 12 项里有 8 项给出了强保护信号(RR )。朴素合并把 TPT Madras 一项的”无效信号”放到最大权重,结论被它拉向接近无效的方向。其他 12 项研究的强保护信号被淹没了。
如果一项研究因为样本量极大就单独决定全球答案,那么做 meta 分析就失去了意义。
要做合理的合并,必须想办法让每项研究”按精度发言”,不让一项大研究把其他 12 项的信号全部淹没。这是第 4 章固定效应模型的任务。
1.6 全书章节与方法路线
到这里第 1 章把数据基本面摆清楚了:13 项试验装成 13 张 2x2 表,每张表算一个 RR,13 项 RR 跨度从 到 ,朴素合并被一项大研究主导得到 但靠不住。后续章节按一条主线把这件事一步步解决。
第 2 章先暂停统计本身,讲 13 项 RCT 是怎么从全球文献库里筛选出来的。这个流程叫 PRISMA,是任何系统综述的开场白。第 3 章回到数字,把 RR 之外的几种常用效应量(OR、风险差、Hedges’ )也讲清楚。第 4 章解决朴素合并的问题,引入固定效应模型,按方差倒数加权让每项研究”按精度发言”。但 BCG 数据上会出现一个新问题:四项研究就占了 86% 的权重,结论仍然被它们主导。第 5 章承认 13 项研究本来就不一样,引入随机效应模型。第 6 章把”研究本来就不一样”的程度量化成 、、 三个数字,叫异质性诊断。第 7 章发现纬度能解释 75% 的研究间差异,这是 BCG 数据最重要的方法学发现。第 8 章质疑:13 项研究就是全部吗,还是有阴性结果根本没发表(发表偏倚)。第 9 章去掉一项研究后结论是否还成立(敏感性分析)。第 10 章把所有方法的结论汇总,给一份临床证据等级(GRADE)。
整本书是一份数据 + 一条主线:每章解决主线上的一个具体问题,章末把那一步的结论汇入对比表。读完全书,你应当能清楚地说出 BCG 在全球的整体效应是多少、不同地区有多大差异、这份证据值多少。
1.7 本章知识地图
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| 2x2 表 | 处理组与对照组在结局上的四格人数 | 只关心发病数,忽略未发病数 | 没有 、 就算不出发病率,更算不出 RR |
| 风险比 RR | 处理组发病率与对照组发病率之比 | RR 越小效果越显著 | RR 衡量相对效应,要配合基线风险看绝对效应 |
| 朴素合并 | 各研究 2x2 表对应格子直接相加再算 RR | 样本量大就权重大、结论更可信 | 等价于按总人数加权,单一巨研究即可主导结论 |
| 全球结论矛盾 | 13 项 RR 从 0.20 到 1.56 跨度极大 | 拿一项研究下结论 | 任何单项都不能代表全球;必须 meta 分析综合 |
| 纬度伏笔 | 低纬度 RR ≈ 1,高纬度 RR ≈ 0.25 | 巧合 | 第 7 章 meta 回归会解释 75.6% 的研究间差异 |