本章目录
本章目录
看清第 1 章那 13 项 RCT 是按什么标准从全球文献库里筛出来的;学会 PICO 框架把研究问题写清楚;学会双人独立筛选与 Cohen’s 一致性度量;理解 Cochrane RoB 2 五个偏倚域,给每项研究的执行质量打分。
第 1 章把 13 项 BCG 试验的数字一字排开,给了我们答案矛盾的真实图景,但跳过了一个关键的前提问题:这 13 项试验是怎么从全球文献库里挑出来的?为什么是 13 项,不是 30 项或 5 项?换一个研究团队复现同样的检索流程,会得到一样的研究列表吗?
这些问题不回答,再精巧的统计合并都建在沙地上。本章讲的不是统计方法,而是 meta 分析”动手算之前”必须走完的检索、筛选、提取、报告流程,行业称为 PRISMA 方案。
1990 年代之前的所谓”综述”,多数是 narrative review。作者根据自己的阅读经验挑选若干”代表性”研究讲故事,挑选标准不公开、过程不可复现、不同作者得出相反结论是常态。1993 年成立的 Cochrane 协作网开始系统性地推动综述流程的标准化,1999 年 QUOROM 声明问世,2009 年扩展为 PRISMA 声明,2020 年 Page 等人发布 PRISMA 2020 更新版。 Page, M. J. et al. (2021). The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ, 372, n71. 今天任何想发表 meta 分析的论文,几乎都被要求附上一张 PRISMA 流程图。
2.1 PRISMA 2020 与四阶段流程
PRISMA 的全称是 Preferred Reporting Items for Systematic Reviews and Meta-Analyses,中文常译为系统综述与 meta 分析报告规范。它不是一种统计方法,而是一份报告清单与一张流程图,规定了一份合规系统综述需要交代清楚哪些信息。PRISMA 2020 把整个研究过程划分成四个阶段,每个阶段都有具体的数字记录。
把这套流程画成图就是经典的 PRISMA 流程图,形状像一个倒置的漏斗:上方是大量候选记录,下方是少数最终纳入的研究。本书数据集 dat.bcg 是 Colditz 1994(JAMA 271(9):698–702)所选定的 13 项 BCG vs no-BCG 随机对照试验。Colditz 1994 检索了 MEDLINE 1966–1992 数据库并通过文献追溯补充,最终纳入 14 项试验,其中 13 项具备完整 2x2 计数数据进入 metafor 包的 dat.bcg。Colditz 1994 发表于 PRISMA 标准建立之前,原文未按 PRISMA 报告每个阶段的具体记录数。
R 包 PRISMA2020 提供了 PRISMA 2020 规范的流程图绘制工具,常用于研究者完成自己的系统综述后生成最终流程图。下面这段代码读入官方 CSV 模板、把 dat.bcg 已知的真实事实填入(最终纳入 13 项研究),中间阶段保留为模板占位符,生成下图。读者在做自己的系统综述时,把每个阶段的真实数字依次填入即可。
R 代码片段 展开
library(PRISMA2020)
# 读入 PRISMA2020 官方 CSV 模板
csv_path <- system.file("extdata", "PRISMA.csv", package = "PRISMA2020")
prisma_df <- read.csv(csv_path)
fill_n <- function(df, key, val) {
df$n[!is.na(df$data) & df$data == key] <- val; df
}
# 中间阶段保留模板占位符
prisma_df <- fill_n(prisma_df, "database_results", "n = ?")
prisma_df <- fill_n(prisma_df, "duplicates", "n = ?")
prisma_df <- fill_n(prisma_df, "records_screened", "n = ?")
prisma_df <- fill_n(prisma_df, "records_excluded", "n = ?")
prisma_df <- fill_n(prisma_df, "dbr_sought_reports", "n = ?")
prisma_df <- fill_n(prisma_df, "dbr_assessed", "n = ?")
# dat.bcg 真实事实:Colditz 1994 最终纳入 13 项 RCT
prisma_df <- fill_n(prisma_df, "new_studies", "13")
prisma_df <- fill_n(prisma_df, "total_studies", "13")
prisma_obj <- PRISMA_data(prisma_df)
plot <- PRISMA_flowdiagram(prisma_obj,
previous = FALSE, other = FALSE,
detail_databases = TRUE, fontsize = 10)
PRISMA_save(plot, filename = "figure/chap02_prisma_flow.pdf",
filetype = "PDF", overwrite = TRUE)
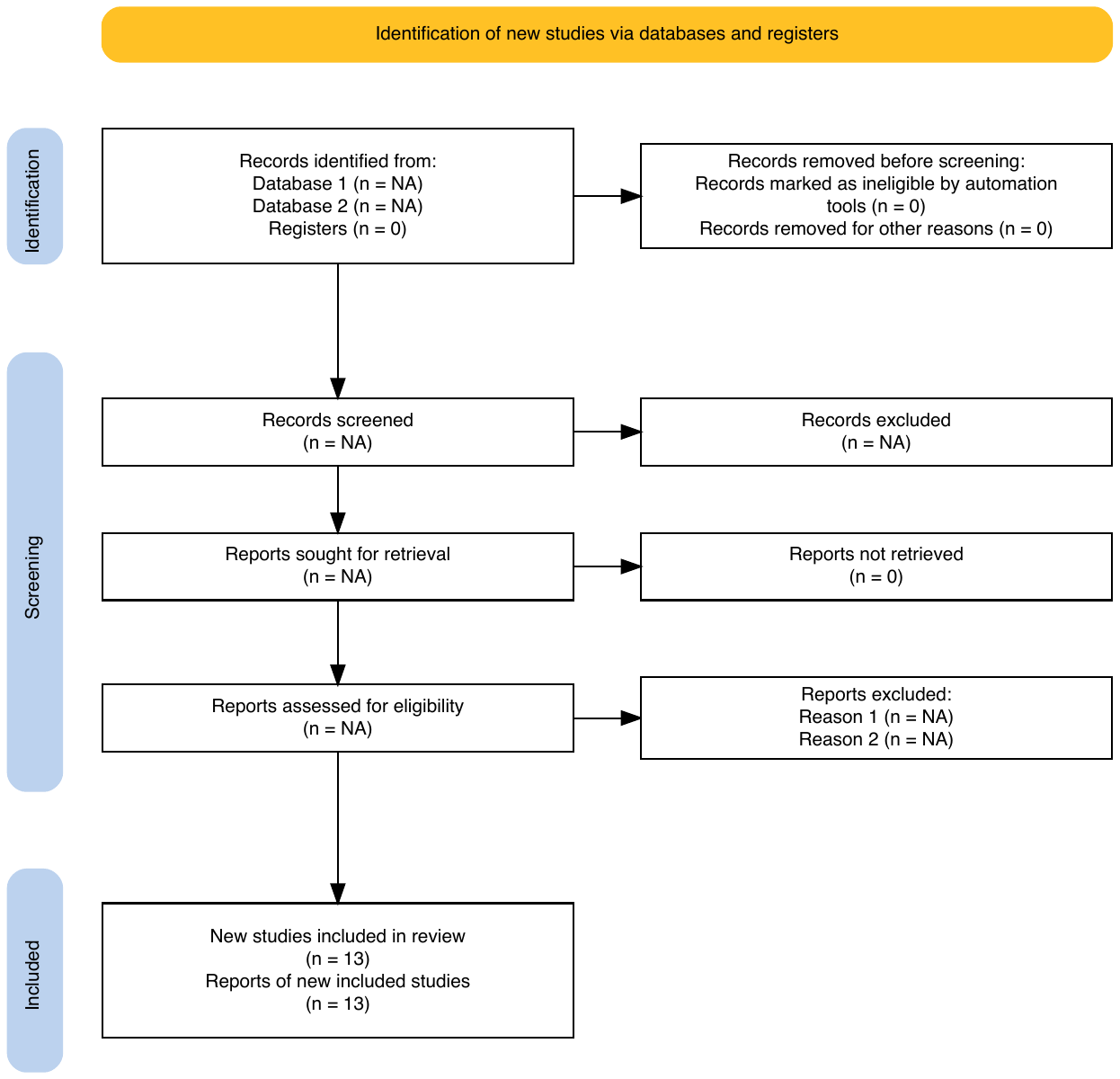
PRISMA 流程图的价值有两层。第一层是可复现性:换一个团队按同样的检索式和筛选标准重新走一遍流程,应该能得到接近的最终研究列表。如果两次结果差异巨大,说明流程的某个环节没记录清楚。第二层是透明审稿:审稿人和读者扫一眼流程图就能定位到可疑环节。比如最后纳入只有 3 项研究但识别阶段就有 5000 条记录,意味着排除率超过 99%,纳入标准可能过严,或者检索关键词不准确。
2.2 PICO 框架与检索式构造
要从茫茫文献库里准确找到与你的研究问题相关的论文,得先把研究问题本身写清楚。“BCG 有效吗”这种宽泛问题没法直接翻译成检索式。临床流行病学界常用的结构化模板叫 PICO 框架,把研究问题拆成四个维度。
PICO 的好处可以用点餐场景来打比方。你跟服务员说”我想吃点东西”,服务员没法办;说”中餐、辣口、人均 50 块、午餐时段”,服务员才知道往哪儿推。PICO 就是把研究问题具体化到能直接送进数据库检索的程度。BCG 这本书的研究问题用 PICO 写出来如下:
| 维度 | 具体内容 |
|---|---|
| P:目标人群 | 健康人群,无活动性结核病史,包括婴儿、儿童、青少年与成人 |
| I:干预 | 接受 BCG 卡介苗接种 |
| C:对照 | 不接种或接种安慰剂 |
| O:结局 | 任意形式的结核病发病,包括肺结核与肺外结核 |
PICO 填好之后,下一步是把每个维度翻译成数据库的检索关键词。一个好的检索式必须覆盖同义词与不同写法,否则会漏掉相关研究。BCG 这个干预在文献里既写作”BCG”,也写作”Bacillus Calmette-Guérin”、“卡介苗”、“卡介苗接种”。结核病既有”tuberculosis”,也有”TB”、“pulmonary tuberculosis”、“Mycobacterium tuberculosis”。把这些同义词用 OR 连起来,再用 AND 把不同维度连起来,得到一个 PubMed 检索式雏形:
TEXT 代码片段 展开
((BCG OR "Bacillus Calmette-Guerin"[MeSH])
AND (tuberculosis OR "Mycobacterium tuberculosis"[MeSH] OR TB)
AND (random* OR "controlled clinical trial"[Publication Type]))
里面的 [MeSH] 标记表示 PubMed 的 Medical Subject Headings 主题词检索,比关键词检索更精确,因为 PubMed 已经把同义词归到同一个 MeSH 词下。random* 里的星号是通配符,能同时匹配 randomized、randomised、randomization 等多种变形。
回到 BCG 的具体实践。如果只用 PubMed 一个数据库,检索覆盖会偏向英语文献,漏掉非英语研究和未发表的灰色文献。Cochrane Handbook 推荐至少检索三个数据库:PubMed、Embase、Cochrane CENTRAL。重要研究还应做文献追溯:把已纳入研究的参考文献列表过一遍,把引用过这些研究的后续论文也找出来。这些步骤决定了图 2.1 顶部”识别阶段 “框需要填入的数字。
2.3 筛选流程与 Cohen’s
识别阶段拿到的几百到几千条候选记录,多数是不相关的。筛选阶段的任务是把不相关的排除掉。直接做法是一个研究者一条条读过去打勾,但单人筛选有两个问题:判断标准会随读者疲劳漂移,主观偏好会悄悄进入决策。Cochrane 推荐双人独立筛选:两个研究者背对背各自打勾,对比两份结果,分歧时第三人裁定或共同讨论。
两个人独立打勾之后,第一个要回答的问题是:他们的判断到底有多一致?最朴素的指标是观察一致率,记作 ,等于两人判断完全相同的记录数除以总记录数。但 有一个明显的缺陷:即使两人完全瞎打勾,纯靠运气也会有相当比例的一致。
举个具体例子。100 篇候选论文里,两位审阅员 A 和 B 独立判断是否纳入。下表把他们的结果交叉列出。
| B 纳入 | B 排除 | 合计 | |
|---|---|---|---|
| A 纳入 | 25 | 5 | 30 |
| A 排除 | 3 | 67 | 70 |
| 合计 | 28 | 72 | 100 |
观察一致率 ,看起来非常好。但纯靠运气也能拿到不少一致。如果 A 平均纳入率是 30%,B 平均纳入率是 28%,假设两人独立瞎打勾(互不相干),“两人都纳入”的随机概率是 ,“两人都排除”的随机概率是 ,偶然期望一致率 。也就是说,即使两人完全瞎打,单纯由于”纳入率本身偏低”,也会有大约 59% 的记录恰好被两人一致判断。0.92 的观察一致率扣掉这 0.59 的偶然部分,剩下的才是真一致。
把表 2.2 的数据代进去:。0.806 在 Landis & Koch 1977 的常用解读里属于”几乎完美一致”。
与 在不同边际分布下会拉开。把同一个 配上不同的纳入率:两人都打 70%(),,,与 0.806 接近。换一种极端:两人都很挑剔,纳入率都只有 5%(),,,跌到”差”一档。同样的 ,因为绝大多数文献本来两人都不会纳入,“瞎打”也能拿到 0.905 的偶然一致,扣除偶然部分后 几乎为零。这就是 Feinstein & Cicchetti 1990 命名的 “kappa 悖论”:高观察一致不必然意味着高真实一致。
Landis-Koch 的常用区间标准(简化版): 一致性差,– 中等,– 良好, 几乎完美。系统综述的筛选阶段一般要求 ,否则说明纳入排除标准本身太模糊,需要重新讨论。 是大多数 Cochrane 综述报告的目标值。
2.4 数据提取与 Cochrane RoB 2
筛选完成、最终纳入的研究列表确定下来之后,下一步是从每篇研究里提取需要的数字。对一份 meta 分析来说,至少要提取每项研究的样本量、处理组与对照组的事件数或均值方差、随机化方式、随访时间、关键基线协变量。提取这一步同样要求双人独立操作,理由与筛选阶段相同。
数据提取之外,每项研究还要做风险偏倚评估。同样是 RCT,执行质量可以差很远:随机化序列是用电脑生成还是用奇偶日期决定?盲法是双盲、单盲还是开放?失访比例多少?预设的主要结局有没有变?Cochrane 在 2019 年发布了第二版风险偏倚工具,英文称 Risk of Bias 2,简称 RoB 2,把风险偏倚拆成五个域来分别评估。
每个域查的是什么。随机化过程域查的是序列生成与分配隐藏:电脑生成的伪随机序列加密码信封是低风险,按入院日期奇偶分组就是高风险,因为研究者能预测下一个进来的病人去哪一组。对预期干预的偏离域查的是参与者与研究人员是否盲法,盲法不全的研究里研究者可能为治疗组病人额外多做几次检查,这种”小心呵护”会污染结果。缺失结局数据域查的是失访比例与失访原因,失访超过 20% 且原因与处理相关时结果可信度就要降级。结局测量域查的是测量人是否盲法、测量方法是否一致。选择性报告域查的是研究是否预先注册了主要结局,发表的论文是否报告了所有预先承诺的结局。
回到 BCG 13 项 RCT。从第 1 章表 1.2 可以看到,13 项研究中 8 项(包含 random 与少量 alternate 实际为 random 的)属于标准随机化路径,2 项是 alternate(按入院顺序交替分配),3 项是 systematic(按某种系统规则分配,如出生日期奇偶)。后两类按今天的标准都属于”准随机”,分配方式可被预测,按 RoB 2 是有些担忧或高风险。这意味着这 13 项研究的偏倚风险并不均匀,第 5 章随机效应模型与第 9 章敏感性分析都会回到这个事实。
2.5 本章小结
整理 13 项研究的检索、筛选、提取、偏倚评估流程本身不产生新的合并估计,对比表暂不更新。从第 4 章固定效应模型开始,每章会在对比表里加一行。下一章先回到统计本身,把第 1 章只讲过 RR 之外的几种常用效应量(OR、RD、log RR 与方差)讲清楚。