本章目录
本章目录
学会把 RR 取对数变成 log RR,看清”对称合并”的需要;掌握 log RR 的方差公式与”事件数决定方差”的事实;理解比值比 OR 与风险差 RD 各自适合什么场景;学会用 escalc() 一站式算出每项研究的效应量与方差。
第 1 章给每项研究算了一个 RR,把 13 项的结果摆在桌面上。第 2 章讲了 13 项试验是怎么被筛进 meta 分析的。从本章起进入”动手合并”前的最后准备:每项研究不仅要有一个效应量数字,还要带上一个不确定性数字(方差)。第 4 章固定效应模型按方差倒数加权时,需要的就是这两件东西。
本章把”动手合并”前需要的术语补齐:log RR 与方差(第 4 章会直接用),OR 与 RD 作为 RR 的两个亲戚(不同研究有时报告不同效应量)。
3.1 对数风险比 log RR
第 1 章的 RR 用起来很顺,但有一个数学上的别扭。“风险降一半”对应 RR ,“风险翻倍”对应 RR 。直觉上这两个效应”大小相等、方向相反”,可在原始数轴上 0.5 离 1 有 0.5 的距离,2 离 1 有 1 的距离,远远不对称。如果你把若干研究的 RR 排在数轴上,“保护”和”有害”两边的视觉重量是不一样的。
解决办法是给 RR 取自然对数。原数轴上 0.5 和 2 不对称,取对数后变成 和 ,正负完全对称。原数轴上 0.25 和 4 不对称,取对数后变成 和 ,也对称起来。“保护一半”和”风险翻倍”在数轴上就是镜像。
对数尺度还有第二个好处。统计学里有一条经验:一个量是若干小因素相乘得到的(如风险比是事件率的比值),它在原始尺度上分布偏斜,取对数之后近似对称、近似正态。后续合并、计算置信区间都依赖正态近似,必须在对数尺度上做才合法。
回到 Aronson 1948。第 1 章算出 ,取对数得到 。第 4 章要合并 13 项 而不是 13 项 。
3.2 log RR 的方差
每项研究给出的 都是一个估计,估计就有不确定性。这种不确定性怎么衡量?
用一个完全不需要医学背景的例子建立直觉:抛一枚均匀硬币,正面概率是 0.5。抛 10 次,你看到 6 次正面(比例 0.6)不算意外;甚至看到 4 次或 7 次都很常见。再抛 1000 次,正面比例几乎一定在 0.48 到 0.52 之间,你看到 0.6 就会怀疑硬币不均匀。同样是估计”正面概率 “这个事实,10 次的估计”晃”得很厉害,1000 次的估计稳得多。
方差是这种”晃动幅度”的数学度量。方差越小说明估计越稳,方差越大说明估计越晃。对一个估计的 来说,统计推导给出的方差近似公式是 2x2 表四个格子的部分倒数和。
把 Aronson 1948 代入:,
四个分项保留三位小数累加得 0.326,与 metafor 用 escalc() 跑出的高精度结果 0.3256 一致。
决定方差大小的不是总样本量,是事件数。
一项研究招了 10 万人但 BCG 组只发生 1 例结核、对照组也只 2 例,方差仍然很大,因为四个分项里有两个分母极小。这是临床流行病学常踩的坑:动辄几十万人的大样本研究在罕见结局上仍可能统计精度很差。
3.3 比值比 OR 与对数比值比
二分类结局除了 RR,还有一种常用效应量叫比值比(odds ratio,简称 OR)。理解 OR 之前先理解比值(odds)本身。
日常语言里”概率”和”比值”经常混用,但它们是两个不同的量。100 个人去做体检,5 个人查出胃部不适。“概率”是 —— 查出不适的人占总人数的比例。“比值”是 —— 查出不适的人对没查出的人。比值没有上限,因为分母可以任意小。事件率低时,5/95 与 5/100 非常接近;事件率高时,比如 50 个查出不适,比值 ,概率 50%,二者拉开差距。
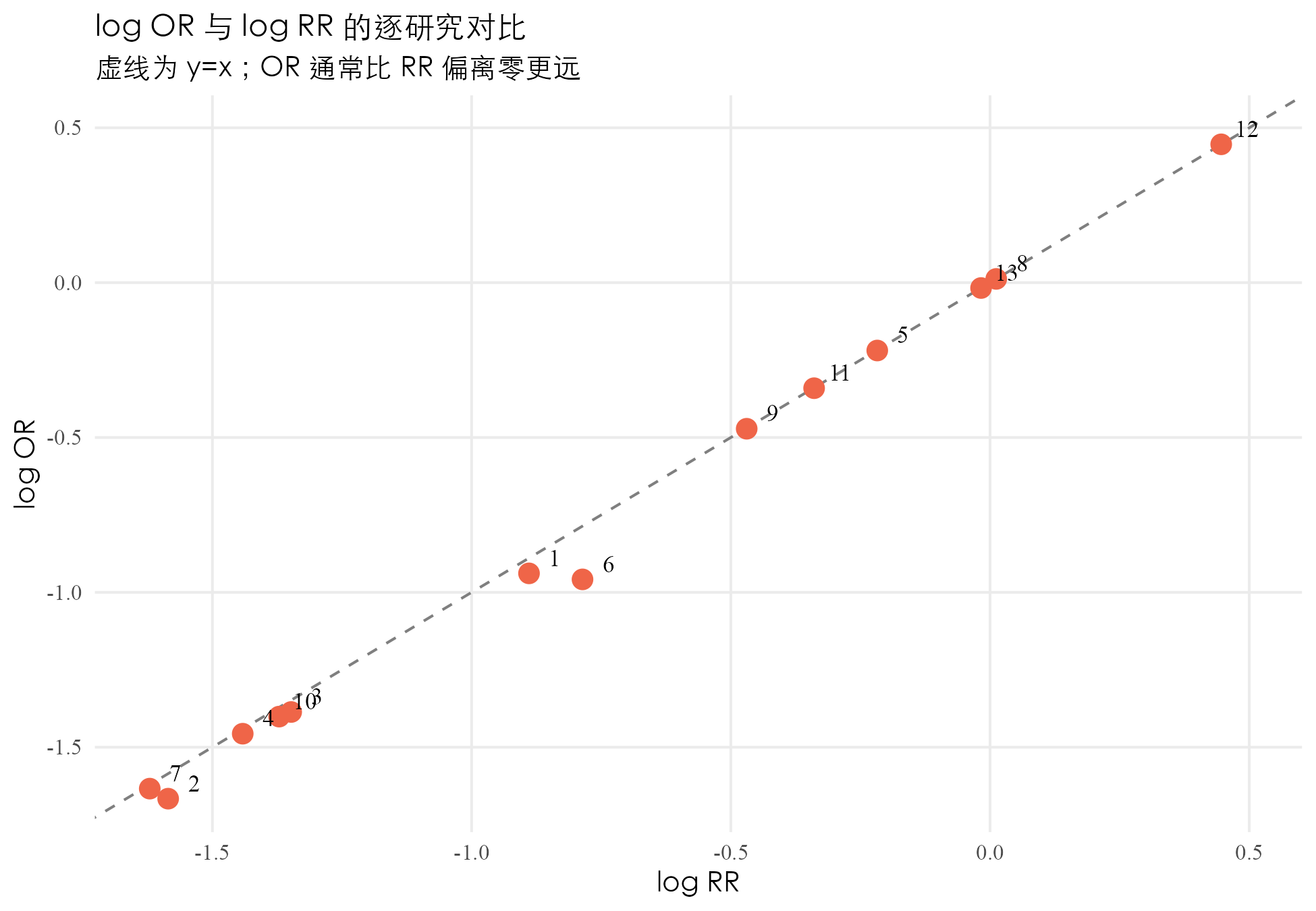
OR 就是两组比值的比。继续吃辣的例子:100 个吃辣的人 5 个胃疼(吃辣组的 odds = 5/95),100 个不吃辣的人 1 个胃疼(不吃辣组的 odds = 1/99)。OR 。回想 RR:。OR 比 RR 略大一点,原因是事件率不为零,吃辣组的分母从 100 缩到 95(少了 5),不吃辣组的分母从 100 缩到 99(只少 1),分母收缩不对称把 OR 推得比 RR 更远离 1。
OR 与 RR 在罕见事件下接近。事件率低时 ,OR 与 RR 数值接近。BCG 数据里大多数研究的结核发病率都在百分之几以下,所以 OR 与 RR 应该非常接近。在 dat.bcg 上跑一遍验证:
R 代码片段 展开
library(metafor)
d <- read.csv("data/bcg.csv")
# 一次性算 RR 和 OR
es_rr <- escalc(measure = "RR", ai = tpos, bi = tneg,
ci = cpos, di = cneg, data = d)
es_or <- escalc(measure = "OR", ai = tpos, bi = tneg,
ci = cpos, di = cneg, data = d)
# 取指数变回原尺度,对比 RR 和 OR
data.frame(
trial = d$trial,
author = d$author,
RR = round(exp(es_rr$yi), 3),
OR = round(exp(es_or$yi), 3),
diff_pct = round((exp(es_or$yi) - exp(es_rr$yi)) /
exp(es_rr$yi) * 100, 1)
)
13 项研究里多数 OR 与 RR 的偏差在 5% 以内。偏差最大的两项是 Stein & Aronson 1953(,,OR 比 RR 小约 16%)和 Ferguson & Simes 1949(,,OR 比 RR 小约 8%)。这两项研究事件率较高:Stein & Aronson 1953 对照组结核发病率约 25.6%(372/1451),处理组也有 11.7%(180/1541),事件率离”罕见”已经很远,OR 比 RR 偏离零的距离更明显。其余 11 项研究事件率都在 1%–6%,OR 与 RR 几乎重合。
3.4 风险差 RD
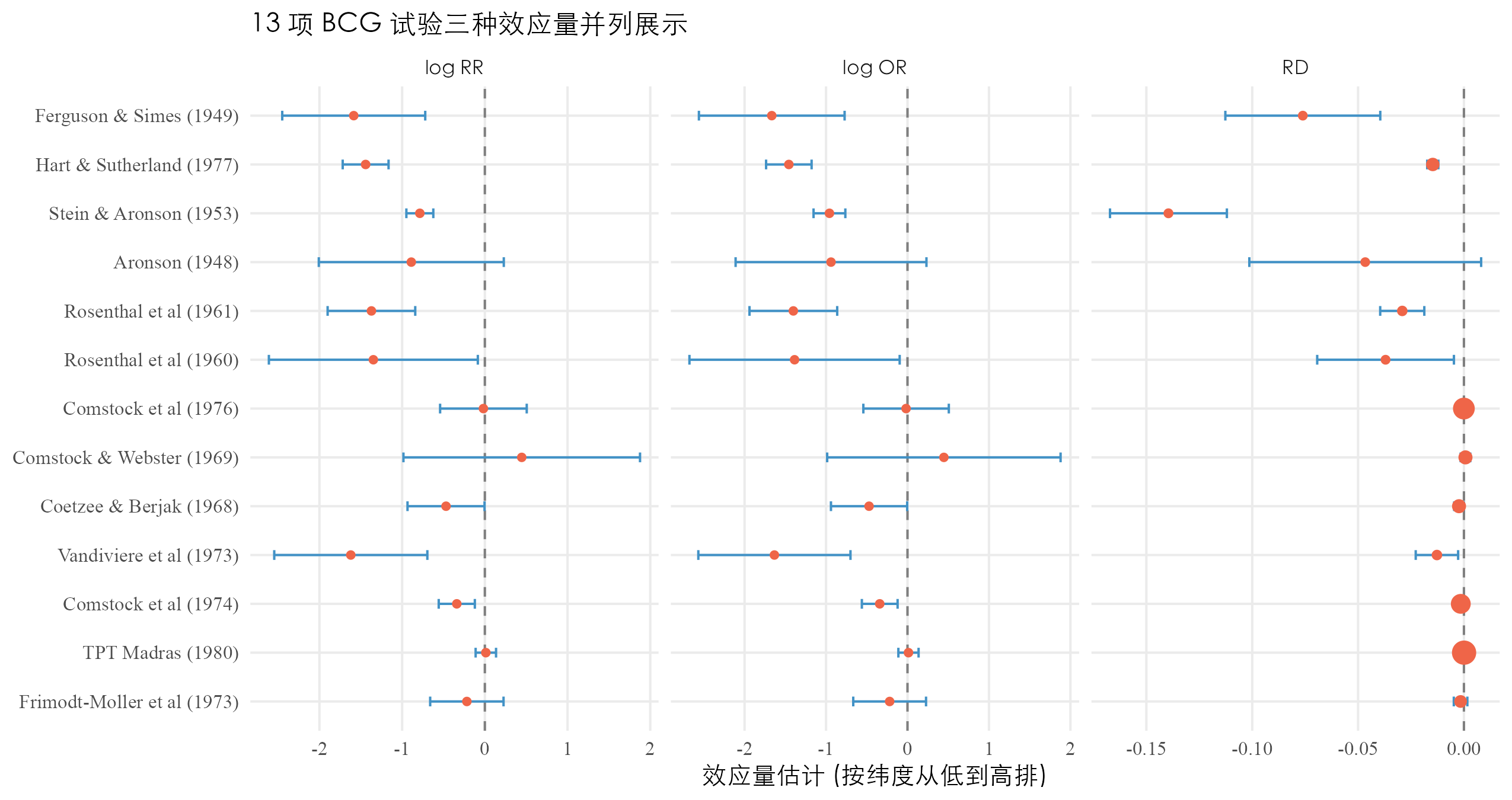
RR 与 OR 都是相对效应量,回答”风险是几倍”的问题。临床决策很多时候需要的是绝对效应量,回答”打疫苗能少多少人发病”的问题。这就是风险差(risk difference,简称 RD)。
继续吃辣的例子:100 个吃辣的人 5 个胃疼,100 个不吃辣的人 1 个胃疼。 个百分点。意思是吃辣比不吃辣绝对增加了 4% 的胃疼风险。如果一个医院每天 1000 个人吃辣,每天就多出 40 个胃疼患者。RD 的好处是它能直接翻译成”打多少人能预防一例发病”,这个倒数叫做 NNT(number needed to treat),临床决策最关心的指标。
RD 与 RR / OR 有一个根本不同:RD 不需要取对数。RR 与 OR 是比值,原尺度上保护和有害不对称,必须取对数才能让正负效应对称合并。RD 是差值,原尺度上 与 已经天然对称,直接合并即可。
把 Aronson 1948 代入 RD 公式:,,。意思是接种 BCG 比不接种绝对降低了约 4.66 个百分点的发病风险。
回到 BCG 数据。13 项研究的 RD 跨度从 (Stein & Aronson 1953)到 (Comstock & Webster 1969)。Stein & Aronson 的 RD 含义是:每 100 人接种 BCG,比不接种少 14 人发生结核 —— 这是绝对意义上巨大的预防效应。Hart & Sutherland 1977 的 RD 是 (每 100 人少 1.47 人发生结核),RR 看起来效果很大,但绝对差小得多,因为这项研究对照组基线发病率本来就只有 1.93%。这说明同一项研究 RR 看起来效果很大、RD 看起来效果很小,是基线风险低的直接结果。
3.5 escalc 函数:一站式计算
前面演示了 escalc() 计算 RR 和 OR。它支持的 measure 选项覆盖了 meta 分析常用的所有效应量。
| measure | 效应量 | 适用场景 |
|---|---|---|
"RR" | log 风险比 | 二分类结局,RCT 默认选择 |
"OR" | log 比值比 | 二分类结局,病例对照或 logistic 回归输出 |
"RD" | 风险差 | 二分类结局,临床绝对效应 |
"PETO" | Peto OR | 罕见事件(事件率通常 且组间事件数接近时) |
"SMD" | Hedges’ | 连续型结局,跨量表合并 |
"MD" | 均值差 | 连续型结局,量表一致 |
"COR" | Pearson | 相关系数 meta 分析 |
"ZCOR" | Fisher | 相关系数(对数尺度合并) |
escalc() 返回一个数据框,包含 yi(效应量估计)和 vi(方差估计)两列。这两列是后续所有 meta 分析函数(rma()、rma.mv())的标准输入。本书 BCG 数据是二分类结局,所有合并都用 measure = "RR"。
完整运行版本见 code/chap03.R 。
3.6 本章小结
每项研究的 与 是合并的输入。第 4 章用这两个数字按”方差越小、发言权越大”的逆方差加权,把 13 项研究合并成一个全局估计 。但 13 项研究的方差极不平衡,最大的 TPT Madras 一项就占 41% 权重,前 4 项合计占 86%,结论仍然被少数大研究主导,异质性指标 也直接证伪 FE 模型的核心假设。这是第 4 章的主要发现,也是引出第 5 章随机效应模型的起点。