本章目录
本章目录
理解固定效应模型的核心假设:所有研究估同一个真实效应;看清逆方差加权的设计动机;学会用 rma() 与 rma.mh() 拟合两种固定效应估计;在 dat.bcg 上读懂 forest plot 与异质性 的红灯信号。
第 1 章朴素合并把 13 张 2x2 表叠加得到 ,但被一项 17.6 万人的 TPT Madras 单独主导,结论被它拉向接近无效的方向。本章引入 meta 分析的第一种正式合并方法 —— 固定效应模型(fixed-effects 或 equal-effects),让每项研究”按精度发言”而不是”按样本量发言”。
4.1 为什么不能按样本量加权
回顾朴素合并失败的原因:把 2x2 表对应格子相加,相当于把每项研究按”样本量”加权。TPT Madras 一项 17.6 万人,权重接近一半,直接把合并结果决定了。
最自然的修补思路是:别按样本量加权,按精度加权。精度高的研究权重大,精度低的研究权重小。第 3 章已经讲过,每项研究的 估计有方差 ,方差越小代表估计越精确。所以”按精度发言”在数学上就是权重 ,叫做逆方差权重。
用一个完全不需要医学背景的例子建立直觉。班里讨论”今天食堂的菜咸不咸”,吃了三大碗的同学(精度高、方差小)说话有分量,只闻了一下饭味的同学(精度低、方差大)声音被淡化。逆方差权重做的就是这件事:让样本量大、事件多的研究主导合并结果,但对真正”精度差”的研究压低声音,不像朴素合并那样让单一巨研究决定一切。
对照一下 BCG 数据。TPT Madras 的方差 ,权重 ;Aronson 1948 的方差 ,权重 。两项研究权重比 81:1。Hart & Sutherland 1977 的 ,权重 。三项的相对发言权 250 : 50 : 3.07,比”按总样本量发言” 176 : 26.5 : 0.262 的 670:1 比例温和不少。
4.2 固定效应模型的假设
逆方差加权法的合理性建立在一条统计假设上:13 项 BCG 试验估的是同一个真实效应,研究之间的差异完全来自抽样波动。
这条假设在临床流行病学里很少真正成立。Hart & Sutherland 1977 的英国受试者和 TPT Madras 1980 的印度南部受试者,年龄构成、营养状况、当地结核流行株系、环境暴露都可能不同,BCG 在两群人身上的”真实效应”很难被论证为完全相同。作为统计基线,FE 模型在它的假设下有解析最优解(最小方差线性无偏估计),是理解后续随机效应模型的起点。
4.3 逆方差加权法
为什么是逆方差而不是别的权重形式?方差小的研究噪音少,把它的估计”压低声音”等于浪费信息;方差大的研究噪音多,把它的估计”放大声音”等于让噪音主导。两项研究 与 ,逆方差权重 给出 25 与 6.25,方差差 4 倍权重就差 4 倍。这种”按精度的反比”分配恰好让总方差最小。
下面用 metafor 的 rma() 函数在 BCG 数据上拟合固定效应模型。rma() 是 metafor 的核心函数,参数 method = "EE" 表示 equal-effects(与传统的 fixed-effects 同义)。
R 代码片段 展开
library(metafor)
d <- read.csv("data/bcg.csv")
es <- escalc(measure = "RR",
ai = tpos, bi = tneg, ci = cpos, di = cneg,
data = d)
fe_iv <- rma(yi, vi, data = es, method = "EE")
print(fe_iv)
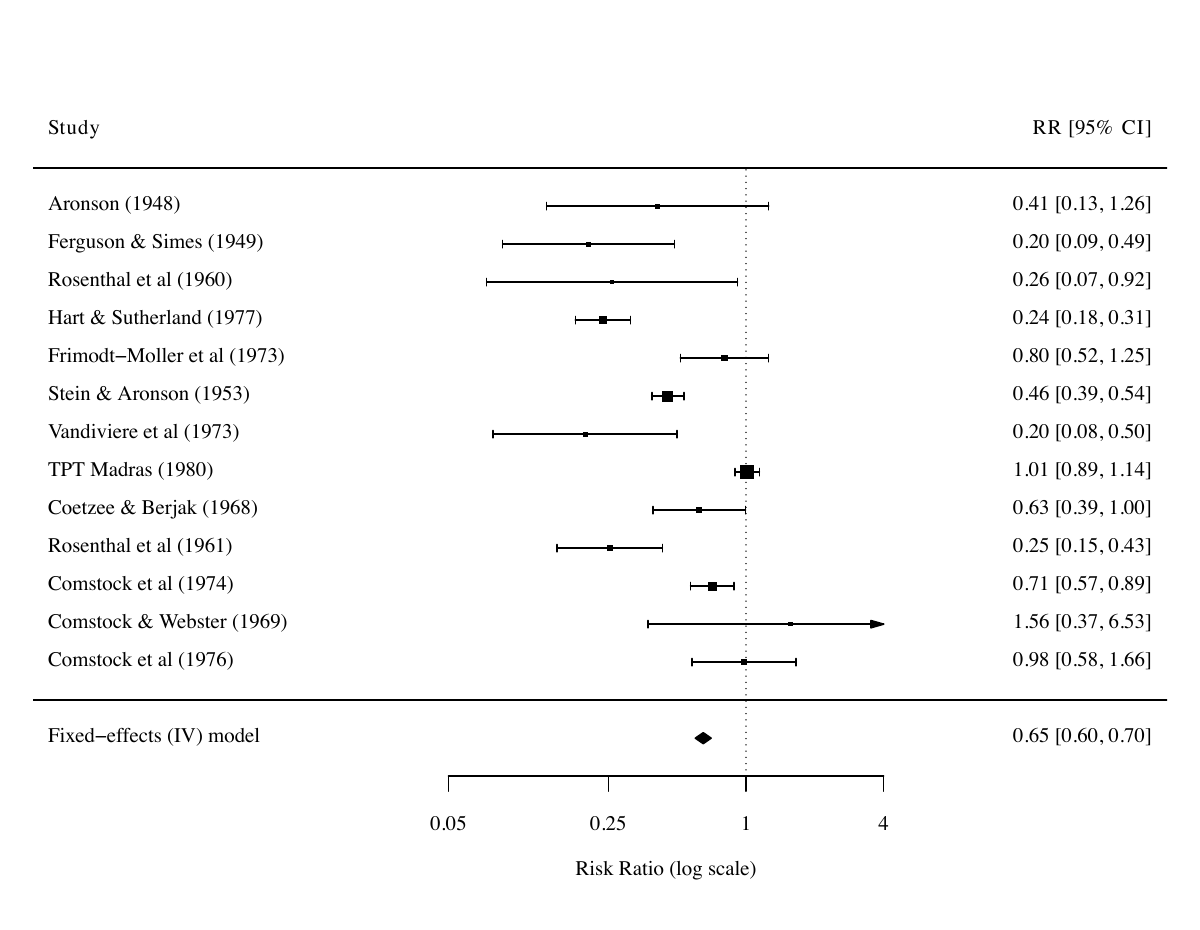
IV 加权固定效应模型给出合并 ,标准误 0.0405,95% CI 。换算到 RR 尺度,合并 ,95% CI 。从这个数字看,BCG 整体把结核风险降低了约 35%。
异质性检验给出 ,自由度 ,,。 把研究间观察变异的超过九成归因于真实的效应异质性,只有不到一成可以用抽样波动解释。这个结果与 FE 模型的核心假设直接冲突:13 项研究几乎可以肯定不是在估同一个真实效应。 与 的正式定义在第 6 章展开。这里先记住一个红灯信号: 超过 50%,FE 模型给出的 CI 几乎一定过窄,结论应当保留质疑。
4.3.1 每项研究的权重分布
逆方差权重让方差小的研究主导结果。下表列出 dat.bcg 13 项研究在 IV 模型下的权重,按权重从大到小排序。
| 编号 | 作者 | 年份 | 方差 | 权重 (%) | 累计 (%) |
|---|---|---|---|---|---|
| 8 | TPT Madras | 1980 | 0.0040 | 41.40 | 41.40 |
| 6 | Stein & Aronson | 1953 | 0.0069 | 23.75 | 65.15 |
| 11 | Comstock et al | 1974 | 0.0124 | 13.21 | 78.36 |
| 4 | Hart & Sutherland | 1977 | 0.0200 | 8.20 | 86.56 |
| 5 | Frimodt-Moller et al | 1973 | 0.0512 | 3.20 | 89.76 |
| 9 | Coetzee & Berjak | 1968 | 0.0564 | 2.91 | 92.67 |
| 13 | Comstock et al | 1976 | 0.0714 | 2.30 | 94.97 |
| 10 | Rosenthal et al | 1961 | 0.0730 | 2.25 | 97.22 |
| 2 | Ferguson & Simes | 1949 | 0.1946 | 0.84 | 98.06 |
| 7 | Vandiviere et al | 1973 | 0.2230 | 0.74 | 98.80 |
| 1 | Aronson | 1948 | 0.3256 | 0.50 | 99.30 |
| 3 | Rosenthal et al | 1960 | 0.4154 | 0.39 | 99.69 |
| 12 | Comstock & Webster | 1969 | 0.5325 | 0.31 | 100.00 |
前 4 项研究合计权重 86.56%,剩余 9 项研究合计权重 13.44%。FE 合并结果几乎是这四项研究的加权平均。回想第 1 章每项研究的 :TPT Madras 是 (几乎无效),Stein & Aronson 是 ,Comstock 1974 是 ,Hart & Sutherland 是 。最大权重的 TPT Madras 把合并拉回到接近零,最强保护的 Hart & Sutherland 因为权重小(8.2%)影响有限。这就是为什么 FE 合并 ,看起来比”按试验平均”温和很多。
朴素合并把 TPT Madras 的”无效信号”放到接近 50% 的样本量份额;FE-IV 把它压到 41% 的精度份额。情形改善但仍不理想 —— 实质问题在 表明的”研究本来就不一样”,第 5 章随机效应模型才能正面解决。
4.4 Mantel-Haenszel 加权
逆方差加权在事件数充足时表现良好,但当某些研究的事件数很少(比如对照组只发生 3 例事件), 会因为方差爆炸而权重过小,甚至 因为零格而无法计算。Mantel & Haenszel 1959 提出了一种不同思路的加权方案,直接基于 2x2 表的格子计数构造合并估计,避开了 的不稳定性。
MH 估计量在稀疏事件下偏倚比 IV 小,是 Cochrane Collaboration 推荐的二分类 meta 分析默认方法。在 BCG 数据上跑 MH 加权:
R 代码片段 展开
fe_mh <- rma.mh(measure = "RR",
ai = tpos, bi = tneg, ci = cpos, di = cneg,
data = d)
print(fe_mh)
MH 合并给出 ,,95% CI 。与 IV 模型的 相比,MH 估计稍稍偏低(保护效应略大),CI 几乎重合。两种方法在 BCG 数据上结论高度一致,原因是 BCG 的事件数普遍充足(最少的 Comstock & Webster 1969 也有 8 例事件),没有触发 IV 加权的稳定性问题。MH 估计的 ,与 IV 几乎一致。
4.5 Forest plot
Forest plot 是 meta 分析最重要的可视化工具,把每项研究的效应估计与合并结果画在同一张图上。读这张图能直接看到三件事:每项研究的效应方向与精度(横线长短)、最大权重的研究是哪几项(方块大小)、研究间散布是否远超单条横线(异质性的视觉证据)。
4.6 累积对比表(首次出现)
从本章起每章在对比表里加一行,到第 10 章合并为终极版。表的设计是把每种方法的合并估计放在同一份模板里,便于横向比较。
| 方法 | 合并 logRR | 合并 RR (95% CI) | 核心假设 | 局限 |
|---|---|---|---|---|
| 朴素合并 | 0.61 (—) | 13 个 2x2 表可直接相加 | 被大样本研究主导,洗掉异质性 | |
| FE-IV | 0.65 (0.60, 0.70) | 13 项研究估同一个真实效应 | ,假设明显违反 | |
| FE-MH | 0.64 (0.59, 0.69) | 同 FE-IV,对稀疏事件更稳健 | 异质性显著时 CI 仍偏窄 |
4.7 本章小结
两种 FE 估计相互验证,但 表明 FE 假设在这份数据上不成立。第 5 章随机效应模型会松开”同一个真实效应”这条假设,给出一个更合理的合并估计。
完整运行版本见 code/chap04.R 。