本章目录
本章目录
用逐步加变量的逻辑回归观察 RHC 系数的漂移,理解回归系数在因果推断语境下的含义与局限,建立全书累积对比表的第一行,看清条件 OR 与边际 OR 的差异以及回归对模型设定的依赖。
上一章用 DAG 确定了调整集:要从 RHC 与 180 天死亡率的关联中剥离混杂,需要控制年龄、性别、APACHE 评分、Glasgow 昏迷评分、合并症等一系列协变量。DAG 告诉我们”该控制谁”,但没有告诉我们”怎么控制”。回归是研究者最熟悉的控制手段,把协变量放进模型右边,让回归方程帮我们”条件化”。
这一章要做的事情很简单:从一个什么都不放的粗模型开始,逐步往回归方程里加入协变量,观察 RHC 的系数怎样随着调整集的扩大而漂移。漂移本身就是混杂被吸收的直接证据。但回归能走多远?它的系数到底在估计什么?它在什么条件下才等价于因果效应?这些问题回答清楚之后,我们才能理解后续章节为什么要引入 G 计算、倾向得分和双重稳健估计。
3.1 从粗关联到条件关联
第 1 章的描述性分析已经给出了一个数字:RHC 组的 180 天死亡率高于非 RHC 组。把这个比较放进逻辑回归的框架,就是只含处理变量的粗模型。
逻辑回归做的事情很直观:给定病人的年龄、APACHE 评分等信息,预测他 180 天内死亡的概率。当我们只放入处理变量 RHC 而不放任何协变量时,模型给出的就是最简单的粗关联。
粗 OR 和因果效应之间隔着整个混杂结构。如果 RHC 的使用与患者病情严重程度相关,而病情严重程度又影响死亡率,那么粗 OR 里既包含 RHC 本身对死亡的影响,也包含”重症患者更容易接受 RHC,同时更容易死亡”这条混杂路径的贡献。回归调整的逻辑是:把混杂变量加进模型右边,让回归方程在协变量的每一个取值水平上比较处理组和对照组的结局差异,从而”堵住”混杂路径。
这个逻辑成立需要一个前提:回归方程的函数形式必须正确。所谓函数形式,指的是模型用什么数学表达来描述协变量与结局之间的关系。最常见的选择是线性项:比如把 APACHE 评分直接放进 ,意思是评分每增加 1 分,log-odds 增加固定的 。
但如果 APACHE 评分与死亡率之间的真实关系是非线性的,比如评分从 10 到 20 影响不大,从 20 到 30 却急剧升高,那么一个线性项就无法捕捉这种弯曲。模型右边虽然放了正确的变量,却没有用正确的方式控制它们,混杂仍然会沿着这条没堵住的路径泄漏进来。这种偏差叫模型设定误差,是回归调整的根本弱点,后面会展开。
3.2 逐步加变量:观察系数漂移
下面我们用 RHC 数据拟合四个嵌套模型。模型 1 是粗模型;模型 2 加入人口学变量 age 和 sex;模型 3 在此基础上加入疾病严重度指标 apache_score 和 glasgow_coma_score;模型 4 进一步加入全部合并症和生理指标。每一步我们只关注 RHC 系数的变化。
set.seed(2026)
library(tidyverse)
library(broom)
d <- read_csv(here::here("data", "rhc.csv"), show_col_types = FALSE) |>
mutate(death180_bin = if_else(death180 == "Yes", 1L, 0L),
sex_bin = if_else(sex == "Male", 1L, 0L))
m1 <- glm(death180_bin ~ rhc, data = d, family = binomial)
m2 <- glm(death180_bin ~ rhc + age + sex_bin,
data = d, family = binomial)
m3 <- glm(death180_bin ~ rhc + age + sex_bin +
apache_score + glasgow_coma_score,
data = d, family = binomial)
m4 <- glm(death180_bin ~ rhc + age + sex_bin +
apache_score + glasgow_coma_score +
cancer + cardiovascular + congestive_hf + dementia +
pulmonary + renal + hepatic + blood_pressure +
heart_rate + respiratory_rate + temperature +
albumin + creatinine + bilirubin + wbc + hematocrit +
das_index + dnr_status + medical_insurance + race +
income + edu + transfer_hx + mi + gi_bleed +
tumor + immunosupperssion + psychiatric,
data = d, family = binomial)
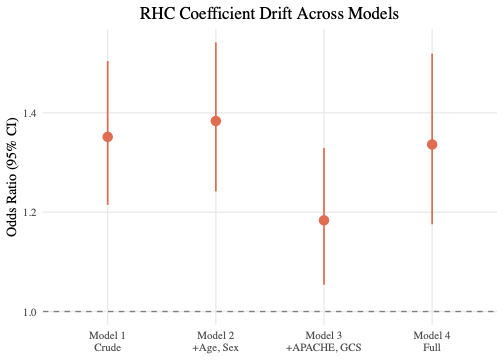
完整代码见 code/chap03.R 。四个模型中 RHC 的 OR 及 95% CI 如下:
| 模型 | OR | 95% CI | 新增协变量 |
|---|---|---|---|
| Model 1 | 1.35 | [1.21, 1.50] | 无 |
| Model 2 | 1.38 | [1.24, 1.54] | age, sex |
| Model 3 | 1.18 | [1.05, 1.33] | apache_score, glasgow_coma_score |
| Model 4 | 1.34 | [1.18, 1.52] | 合并症 + 全部生理指标 |
从模型 1 到模型 2,OR 从 1.35 微升到 1.38。年龄和性别的加入几乎没有改变 RHC 系数,说明这两个变量在 RHC 使用决策中的混杂作用不大。
明显的变化发生在模型 3:加入 APACHE 评分和 GCS 之后,OR 从 1.38 骤降到 1.18,降幅超过 14%。这与预期一致,APACHE 评分是 ICU 里决定是否插管的核心指标,它同时强烈预测死亡率,是经典的正向混杂变量。控制了它,RHC 与死亡之间有一大块虚假关联被剥离了。
模型 4 加入合并症之后,OR 又回升到 1.34。这个反弹说明多放变量不等于更干净。合并症变量中有些可能是中介变量或碰撞因子,也可能是引入了新的模型设定误差。无论原因是什么,系数的非单调漂移提醒我们:回归调整的结果高度依赖模型中放了什么变量、用了什么函数形式。
3.3 系数漂移背后的混杂吸收
为什么加入不同协变量会让 RHC 系数往不同方向移动?回归系数的本质是偏回归系数:它度量的是”在其他所有自变量固定的条件下,该自变量每变动一个单位,结局的对数几率变动多少”。理解偏回归系数有一个经典的思维工具:Frisch-Waugh-Lovell 分解。在线性回归中, 的系数等价于先把 和 各自对其他协变量 做回归,取残差,再用 的残差去预测 的残差。偏回归系数衡量的是”剔除了 能解释的部分之后, 中剩余的变异与 中剩余的变异之间的关系”。
用一个简化的线性模型来看清这个机制:假设真实模型是 ,而我们只拟合了 。遗漏变量偏差公式告诉我们 ,其中 是 对 回归的系数。如果 且 ,偏差 ,粗系数偏高;如果两者符号相反,粗系数偏低。这个公式在逻辑回归中没有精确的对应形式,但方向性的直觉完全适用。
在 RHC 数据中,APACHE 评分与 RHC 使用正相关,因为病情越重的患者越可能被插管;APACHE 评分与死亡率也正相关。两条正关联叠加,意味着 APACHE 评分制造了正向混杂,让粗 OR 偏高。控制 APACHE 之后,这部分虚假的正关联被剥离,RHC 系数下降。
模型 2 中加入年龄和性别后系数微升的现象也有解释。年龄与 RHC 使用之间的关联方向未必是简单的正相关。ICU 里的实际决策逻辑是复杂的:年轻患者如果病情严重,医生更倾向于采取积极干预;但对于高龄患者,即使病情同样严重,医生和家属可能倾向于保守治疗。这种选择偏好意味着年龄与 RHC 使用之间可能存在负向关联。同时年龄与死亡率正相关。按照遗漏变量偏差的方向判断规则,负 正产生负向偏差,意味着粗模型中年龄造成的混杂方向是让 OR 偏低。控制年龄后,这部分负向混杂被移除,OR 反而略微上升。
模型 4 中系数的反弹有不同的来源。OR 从模型 3 的 1.18 跳回到 1.34,几乎回到了粗模型的水平。一种可能是某些合并症变量位于 RHC 和死亡的因果路径上,控制它们会阻断因果中介效应,造成系数偏移。比如如果 RHC 的使用会影响患者后续是否被诊断出某些合并症,那么控制这些合并症就相当于控制了一个中介,打开了从 RHC 到死亡的非因果路径。另一种可能是高维模型中变量之间的共线性改变了回归面的倾斜方式。
回归无法自动判断哪些变量该放、哪些不该放,它只负责在你指定的模型下估计条件关联。DAG 告诉你调整集,回归只是执行调整的计算工具。
3.4 回归的因果解读条件
系数漂移让我们看到了混杂被吸收的过程,但一个更根本的问题还没有回答:即使调整集完全正确,回归系数在什么条件下才等于因果效应?
前两个条件和所有因果推断方法共享,回归独有的额外负担是第三条:模型设定正确。在本章的四个模型中,我们把所有协变量以线性方式放入 logit 链接函数,没有加交互项,没有加非线性变换。如果 APACHE 评分对死亡率的影响存在阈值效应,比如评分超过 30 之后死亡率急剧上升但之前变化平缓,那么一个线性项无法捕捉这种关系。如果 APACHE 与年龄之间存在交互作用,比如高 APACHE 在年轻患者中更致命因为说明病情突然恶化,那么不加交互项就会遗漏这部分效应修饰。线性模型在这些情况下会产生设定偏误,即使调整集完全正确,系数也不等于因果效应。
设定偏误的麻烦在于它是隐性的。模型照样会收敛,照样会给出一个 OR 和一个 值,研究者没有任何自动提示告诉他”你的函数形式错了”。Hosmer-Lemeshow 检验和 AIC 可以给出一些间接信号,但它们检测的是整体拟合优度,对特定系数的偏误不敏感。
回归调整由此要求研究者事先猜对函数形式。协变量少的时候,可以靠领域知识加交互项和样条;协变量多到几十个的时候,交互项的组合空间爆炸,手动设定模型变得不现实。RHC 数据有 49 个变量,光两两交互就有上千项,加上非线性变换,可能的模型空间大到无法手动搜索。
3.5 条件 OR vs 边际 OR
假设我们的模型设定完美无瑕,调整集也毫无遗漏,回归给出的 就是因果效应了吗?答案取决于你想要的是哪种因果效应。
首先说条件 OR。回归给出的 是条件 OR,它回答的问题是:在同一类患者内部,接受 RHC 和不接受 RHC 的人相比,死亡几率比是多少。比如两个 APACHE 评分都是 25、年龄都是 65 岁的患者,一个插了导管一个没插,条件 OR 比较的就是这两个人的死亡几率之比。协变量固定,比较的是”同类人”之间的差异。
其次说边际 OR。很多研究者更关心的是整个人群层面的效应,而非同一协变量组合内部的条件比较:如果所有 5735 名 ICU 患者都接受 RHC,和所有人都不接受 RHC,死亡率会差多少?这就是边际效应。边际 OR 把所有患者混在一起算总体的几率比,不区分 APACHE 高低、年龄大小。
在线性模型中,条件效应和边际效应一致,加不加协变量不影响处理系数的期望值,前提是没有混杂。在非线性模型中两者通常不同,这个差距叫作非压缩性,英文称 non-collapsibility。
用一个具体的数字例子来看。假设有两个 ICU 病房,每个病房各 100 名患者。病房 A 的基线死亡率较高,RHC 组死亡概率 0.80,对照组 0.60,OR = 。病房 B 的基线死亡率较低,RHC 组死亡概率 0.40,对照组 0.20,OR = 。两个病房的条件 OR 完全相同。现在把两个病房的 200 名患者混在一起计算边际 OR:RHC 组总死亡概率 0.60,对照组总死亡概率 0.40,边际 OR = 。同样的条件效应,混合之后数值变小了。这不是混杂造成的,纯粹是 OR 这个度量在合并子群时的数学性质。
非压缩性带来的实际后果是:我们在模型 4 中读到的 OR = 1.34 不能直接解读为”如果所有人都接受 RHC,死亡几率比不接受高 34%“。条件 OR 回答的是”在同一类患者内部,接受 RHC 的人和不接受的人相比如何”,而边际效应回答的是”整个人群层面的平均因果效应”。两者之间的差距不是混杂造成的,纯粹是 OR 这个度量的数学性质决定的。风险差和风险比不存在非压缩性问题,这也是为什么越来越多的流行病学家建议在因果推断中报告风险差而非 OR。
如果我们想要边际效应估计,需要一种不同的计算方式。下一章的 G 计算会用标准化的方式把条件预测平均回全人群,直接在概率尺度上计算边际风险差,从而绕过非压缩性问题。
3.6 回归调整的局限
回归调整是因果估计的起点,但它有几条绕不过去的限制。
回归没有显式地构造反事实。它给出的是一个系数,你需要相信模型的函数形式才能把系数翻译成因果效应。相比之下,G 计算会为每个个体分别预测”如果接受 RHC”和”如果不接受 RHC”两个反事实结局,然后取差值。这种显式构造让反事实推理变得透明。
回归对正值性违反没有内置的警报机制。如果某一类患者几乎全部接受了 RHC,回归仍然会给出一个系数,但这个系数在该子群中几乎完全靠外推。想象一个 APACHE 评分极高的层,里面 98% 的患者都接受了 RHC,只有 2% 没接受。回归在这个层里比较的实际上是 98 个处理样本和 2 个对照样本的结局差异,统计功效极低,估计几乎完全依赖模型的线性外推假设。倾向得分方法至少可以通过检查得分分布来发现这种 overlap 缺失。
回归的第三个局限容易被忽略:它假设处理效应在所有协变量层上是同质的。模型 只给 一个系数 ,意味着 RHC 对年轻人和老年人、轻症和重症的效应都一样。如果真实效应是异质的,一个单一的 会把这些异质性平均掉,得到一个可能误导政策的”平均”估计。
这些局限加在一起,意味着回归调整的结论必须谨慎解读。但这并不意味着回归没用。对于一个探索性分析,逐步加变量的回归能快速揭示混杂结构,帮助研究者判断哪些变量是关键混杂源。
3.7 方法卡与累积对比表
| 方法 | ATE 估计 | 95% CI | 核心假设 |
|---|---|---|---|
| 粗差异 | RD = 0.075 | — | 无 |
| 回归调整 | OR = 1.34 | [1.18, 1.52] | 模型设定正确 + 可交换性 + 正值性 |
下一章的 G 计算会做一件与回归截然不同的事:为每个患者分别预测两个反事实结局,然后用标准化把个体层面的预测汇总为全人群的边际因果效应。提取因果效应的方式从”读系数”转向”构造反事实”。
3.8 本章知识地图
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| 粗 OR | 未调整任何协变量的处理-结局关联 | 粗 OR 就是因果效应 | 混杂未被控制,关联 因果 |
| 系数漂移 | 加入协变量后处理系数发生变化,反映混杂被吸收 | 系数变化一定单调递减 | 变化方向取决于混杂方向,负向混杂会让系数上升 |
| 模型设定正确 | 回归的函数形式必须与真实数据生成过程一致 | 放了正确的变量就够了 | 变量正确但函数形式错误仍然会产生设定偏误 |
| Table 2 Fallacy | 同一回归中所有系数共用一个调整集 | 每个系数都可以解读为因果效应 | 不同因果问题对应不同的 DAG 和调整集 |
| 非压缩性 | 条件 OR 与边际 OR 在非线性模型中不相等 | 调整后 OR 下降一定是混杂被控制 | OR 的数学性质让边际化本身就会改变数值 |
| 回归的局限 | 对函数形式敏感,无显式反事实,无正值性诊断 | 回归能解决所有混杂问题 | 高维、非线性场景下模型设定几乎不可能全对 |