本章目录
本章目录
理解 G 公式的识别结果及其与回归系数的本质区别,掌握 G 计算的三步算法:建模、预测反事实、边际化,在 RHC 数据上实现 G 计算并用 Bootstrap 构造置信区间,更新累积对比表。
上一章用逐步加变量的逻辑回归估计了 RHC 的效应,得到全调整 OR = 1.34,95% CI [1.18, 1.52]。这个数字是从回归方程里”读”出来的:拟合模型,提取 rhc 的系数,做指数变换。整个过程依赖一个隐含的操作,我们信任模型的函数形式,把系数直接翻译成因果效应。
但回归系数回答的问题和因果推断想要回答的问题之间有一道裂缝。
先看回归系数回答的是什么。条件 OR = 1.34 的意思是:在年龄、APACHE 评分等 33 个协变量都固定的某一层里,接受 RHC 的患者相对于不接受 RHC 的患者,死亡几率比为 1.34。它描述的是”层内”的比较。
再看因果推断想回答什么。我们真正关心的问题是:如果 5735 名患者全部接受 RHC,和全部不接受 RHC 相比,180 天死亡率会差多少?这是一个全人群层面的问题,比较的是两个反事实世界的平均结局,得到的量叫边际风险差。
这两个量为什么不一样?上一章已经讲过,逻辑回归有非压缩性:即使每一层内的 OR 都是 1.34,把所有层加权汇总后得到的边际 OR 通常不等于 1.34,更不能直接换算成风险差。条件 OR 和边际风险差在数学上不等价,不能简单地从一个推导出另一个。
G 计算走了一条完全不同的路。它不去读系数,而是用模型为每一个患者分别预测”如果接受 RHC 会怎样”和”如果不接受 RHC 会怎样”,构造出两个完整的反事实人群,然后在全人群上取平均,直接得到边际因果效应。
4.1 从标准化到 G 公式
在正式引入 G 公式之前,需要理解它的直觉来源:流行病学中的标准化率。
先用 RHC 数据看一个具体问题。处理组平均 APACHE 评分更高,意味着病情更重;对照组平均 APACHE 评分更低,病情相对更轻。病情重的人本来死亡率就高,所以直接拿处理组的总死亡率和对照组的总死亡率比较,偏差是必然的。
怎么办?假设 APACHE 评分只有低、中、高三档。低档占全人群 40%,中档占 35%,高档占 25%。我们可以在每一档内分别算处理组和对照组的死亡率,消除病情严重程度的影响,然后按全人群的三档比例加权平均。这就是标准化。
标准化率的思路很简单:如果两组人群的混杂因素分布不同,直接比较总率会产生偏倚,那就把两组的结果都”投射”到同一个标准人群的分布上,消除混杂因素构成差异的影响。
这个手工操作在混杂变量只有一两个的时候可行。一旦混杂变量增加到十个以上,层数呈指数增长,每一层里的样本量很快不够用。RHC 数据有 33 个协变量,如果每个只分两层,就有 超过 80 亿个组合,远远超过 5735 的样本量。传统标准化在高维场景下彻底失效。
G 计算的核心思想是用回归模型替代手工分层。不再把协变量空间切成离散的层,而是用一个回归模型来估计每一层的条件结局概率,然后按全人群协变量的经验分布做加权平均。模型承担了”在每一层内计算率”的任务,经验分布承担了”用标准人群权重加权”的任务。两者结合,就是 G 计算。
假设协变量只有 APACHE 评分,分成低、中、高三档。低档占全人群 40%,处理组在低档内的死亡率为 25%;中档占 35%,处理组死亡率 45%;高档占 25%,处理组死亡率 70%。如果全人群都接受 RHC,预期死亡率是多少?按全人群的三档比例加权平均:。也就是说,全人群层面的 。
这个计算做了两件事:第一,在每一档内算出处理组的死亡率(相当于”条件期望”);第二,按全人群的档位比例加权汇总(相当于”边际化”)。G 公式把这两步写成了一般性的数学表达。
内层期望 对应”在某一档内,处理设定为 时的死亡率”。外层期望 对应”按全人群的档位比例加权平均”。整个操作的效果是:先在 的每一个值上算出处理为 时的结局均值,再按全人群中 实际的分布把这些均值汇总成一个数字。这个数字就是全人群层面的潜在结局期望 。
可交换性在这里的作用是保证内层期望的因果解读。在同一个 值下,如果处理分配与潜在结局独立,那么我们观察到的处理组结局均值 就等于该 层全体人群在设定处理为 时的潜在结局均值 。没有这条假设,我们只是在算条件关联,不是在估计反事实。
4.2 G 计算的三步算法
G 公式给出了识别结果,G 计算是把这个识别结果变成可操作算法的过程。整个算法可以浓缩为三步:建模、预测反事实、边际化。
理解这三步的关键在于第二步。预测反事实的操作是”把每个人的处理变量强制改写,但协变量保持原样”。这和回归的”读系数”有本质区别。回归读的是一个全局系数,它把所有个体的效应压缩成一个数字,并且这个数字的含义受模型函数形式的约束。G 计算做的是为每个人分别算两个预测值,然后在个体层面取差,最后汇总。即使同一个逻辑回归模型,G 计算提取因果效应的方式也和读系数不同,因为它绕过了非压缩性问题,直接在概率尺度上操作。
第三步中用算术平均做边际化,等价于用经验分布 作为权重。这意味着 G 计算标准化到的”标准人群”就是样本本身。每个人贡献相同的权重,不需要手动指定标准人群,也不需要分层。这就是为什么 G 计算能处理高维混杂:模型负责”在每一层内估计率”,经验分布负责”加权”,维度灾难被模型吸收了。
4.3 RHC 数据上的 G 计算实现
本章继续使用 RHC 数据集,。结局模型与上一章模型 4 完全相同:用逻辑回归拟合 180 天死亡对 RHC 和 33 个协变量的关系。区别在于,上一章从这个模型里读 rhc 的系数,本章用这个模型为每个患者预测两个反事实结局。
set.seed(2026)
library(tidyverse)
d <- read_csv(here::here("data", "rhc.csv"), show_col_types = FALSE) |>
mutate(death180_bin = if_else(death180 == "Yes", 1L, 0L),
sex_bin = if_else(sex == "Male", 1L, 0L))
# 建模:与第 3 章模型 4 相同的结局模型
outcome_mod <- glm(death180_bin ~ rhc + age + sex_bin +
apache_score + glasgow_coma_score +
cancer + cardiovascular + congestive_hf + dementia +
pulmonary + renal + hepatic + blood_pressure +
heart_rate + respiratory_rate + temperature +
albumin + creatinine + bilirubin + wbc + hematocrit +
das_index + dnr_status + medical_insurance + race +
income + edu + transfer_hx + mi + gi_bleed +
tumor + immunosupperssion + psychiatric,
data = d, family = binomial)
# 预测反事实:构造两个"平行世界"的数据集
d1 <- d |> mutate(rhc = 1L) # 所有人接受 RHC
d0 <- d |> mutate(rhc = 0L) # 所有人不接受 RHC
Y1 <- predict(outcome_mod, newdata = d1, type = "response")
Y0 <- predict(outcome_mod, newdata = d0, type = "response")
# 边际化:对全人群取算术平均
EY1 <- mean(Y1)
EY0 <- mean(Y0)
RD <- EY1 - EY0
cat("E[Y(1)] =", round(EY1, 4), "\n")
cat("E[Y(0)] =", round(EY0, 4), "\n")
cat("Risk Difference =", round(RD, 4), "\n")
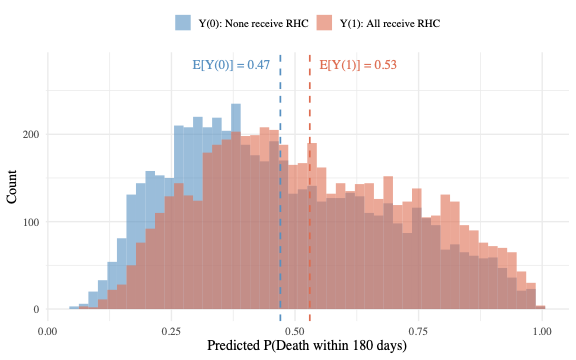
完整代码见 code/chap04.R 。G 计算给出的结果是:如果全部 5735 名患者都接受 RHC,预计 180 天死亡率为 53.0%;如果全部不接受 RHC,预计死亡率为 47.0%。边际风险差 RD = 0.060,即接受 RHC 使 180 天死亡概率升高约 6 个百分点。
这个结果与第 3 章回归的 OR = 1.34 方向一致,都指向 RHC 增加死亡风险。但两者报告的是不同的因果量:回归给的是条件 OR,G 计算给的是边际 RD。RD = 0.060 的临床含义更直接:每 100 名接受 RHC 的 ICU 患者中,大约多 6 人在 180 天内死亡。
4.4 Bootstrap 置信区间
G 计算的点估计有了,但没有置信区间的点估计是不完整的。G 计算的标准误没有简洁的解析公式,因为它涉及模型拟合和非线性预测两个步骤的不确定性叠加。实践中最常用的方法是非参数 Bootstrap:从原始数据中有放回地抽样,在每个 Bootstrap 样本上重复 G 计算的全部流程,用 Bootstrap 分布的百分位数构造置信区间。
Bootstrap 的直觉是”用数据模拟采样变异”。真实世界中我们只有一份数据,没法重复抽样;Bootstrap 用有放回抽样来近似”如果我们能重复收集数据,估计值会怎么波动”。每一次 Bootstrap 抽样都会产生一个略有不同的数据集,从而产生一个略有不同的 G 计算估计。1000 次 Bootstrap 给出 1000 个估计值,这些值的分布就近似了真实的抽样分布。
n_boot <- 1000
boot_rd <- numeric(n_boot)
for (i in seq_len(n_boot)) {
idx <- sample(nrow(d), replace = TRUE)
bd <- d[idx, ]
mod <- glm(death180_bin ~ rhc + age + sex_bin +
apache_score + glasgow_coma_score + cancer + cardiovascular +
congestive_hf + dementia + pulmonary + renal + hepatic +
blood_pressure + heart_rate + respiratory_rate + temperature +
albumin + creatinine + bilirubin + wbc + hematocrit + das_index +
dnr_status + medical_insurance + race + income + edu +
transfer_hx + mi + gi_bleed + tumor + immunosupperssion + psychiatric,
data = bd, family = binomial)
bd1 <- bd |> mutate(rhc = 1L)
bd0 <- bd |> mutate(rhc = 0L)
boot_rd[i] <- mean(predict(mod, bd1, "response")) -
mean(predict(mod, bd0, "response"))
}
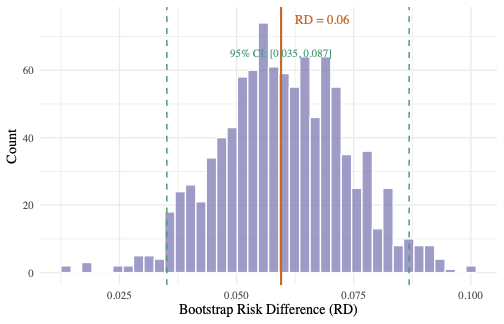
ci <- quantile(boot_rd, c(0.025, 0.975))
cat("Bootstrap 95% CI:", round(ci, 4), "\n")
1000 次 Bootstrap 的结果:RD 的 95% 百分位数置信区间为 [0.035, 0.087]。区间不包含 0,,与回归调整的结论方向一致。Bootstrap 标准误约为 0.014。
4.5 G 计算的局限
G 计算的全部依赖只在一个模型上:结局模型。如果结局模型的设定正确,G 计算给出的是一致的边际因果效应估计;如果结局模型设定错误,G 计算的估计会系统性偏倚,而且没有内置的纠错机制。
这与后续章节将介绍的方法形成对比。倾向得分方法把建模负担转移到处理模型上,只需要正确预测”谁接受了 RHC”,不需要建结局模型。双重稳健方法同时建两个模型,只要其中一个正确就能给出一致估计。G 计算只依赖一个模型,它的稳健性完全取决于这个模型的质量。
G 计算还有一个容易被忽略的假设:它标准化到的是样本的协变量分布。如果样本不代表目标人群,比如 RHC 数据来自 5 家教学医院而研究者想推广到所有 ICU,那么 G 计算的估计只是样本内的 ATE,不是目标人群的 ATE。要推广,需要额外的可迁移性假设。
4.6 方法卡与累积对比表
| 方法 | ATE 估计 | 95% CI | 核心假设 |
|---|---|---|---|
| 粗差异 | RD = 0.075 | — | 无 |
| 回归调整 | OR = 1.34 | [1.18, 1.52] | 模型设定正确 + 可交换性 + 正值性 |
| G 计算 | RD = 0.060 | [0.035, 0.087] | 结局模型正确 + 可交换性 + 正值性 |
两种方法都指向同一个方向:RHC 与更高的 180 天死亡率相关。回归以 OR 的形式报告,置信区间不含 1;G 计算以 RD 的形式报告,置信区间不含 0。两者在核心假设上共享可交换性和正值性,区别在于对模型的依赖方式。回归要求函数形式正确才能让系数等于因果效应,G 计算要求结局模型的预测值整体合理才能让标准化估计正确。
下一章引入倾向得分方法,它完全放弃结局模型,转而建模”谁更可能接受 RHC”。把建模负担从结局端转移到处理端,是因果推断方法论的另一次思路转换。
4.7 本章知识地图
| 核心概念 | 核心内容 | 常见误解 | 为什么错 |
|---|---|---|---|
| G 公式 | 把潜在结局的边际期望分解为条件期望对协变量分布的积分 | G 公式是一种新的回归方法 | G 公式是识别结果,回归只是实现它的一种建模工具 |
| G 计算三步 | 建模 → 预测反事实 → 边际化 | G 计算就是换个方式报告回归系数 | G 计算提取的是边际 RD,与条件 OR 在含义和数值上都不同 |
| 反事实构造 | 对每个个体保持协变量不变,只改处理变量的值 | 预测反事实只用处理组或对照组 | 必须用全样本拟合模型,预测时也对全样本做 |
| 边际 vs 条件效应 | 边际效应是全人群平均,条件效应是协变量固定下的效应 | 控制混杂后 OR 下降就是混杂消除 | 非压缩性让条件 OR 和边际 OR 在非线性模型中天然不等 |
| Bootstrap CI | 用有放回抽样模拟采样变异,构造百分位数 CI | Bootstrap 只是小样本工具 | G 计算没有解析标准误,Bootstrap 是标准做法 |
| 结局模型依赖 | G 计算的因果效力完全取决于结局模型是否正确 | G 计算比回归更可靠 | 共享同一个模型假设,只是效应提取方式不同 |